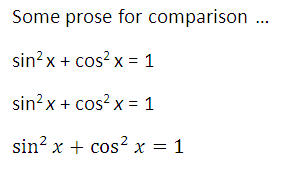Sometimes a number is not a number. Numeric data types represent real numbers in a computer fairly well most of the time, but sometimes the abstraction leaks. The sum of two numeric types is always a numeric type, but the result might be a special bit pattern that says overflow occurred. Similarly, the ratio of two numeric types is a numeric type, but that type might be a special type that says the result is not a number.
The IEEE 754 standard dictates how floating point numbers work. I’ve talked about IEEE exceptions in C++ before. This post is the Python counterpart. Python’s floating point types are implemented in terms of C’s double type and so the C++ notes describe what’s going on at a low level. However, Python creates a higher level abstraction for floating point numbers. (Python also has arbitrary precision integers, which we will discuss at the end of this post.)
There are two kinds of exceptional floating point values: infinities and NaNs. Infinite values are represented by inf and can be positive or negative. A NaN, not a number, is represented by nan. Let x = 10200. Then x2 will overflow because 10400 is too big to fit inside a C double. (To understand just why, see Anatomy of a floating point number.) In the following code, y will contain a positive infinity.
x = 1e200; y = x*x
If you’re running Python 3.0 and you print y, you’ll see inf. If you’re running an earlier version of Python, the result may depend on your operating system. On Windows, you’ll see 1.#INF but on Linux you’ll see inf. Now keep the previous value of y and run the following code.
z = y; z /= y
Since z = y/y, you might think z should be 1. But since y was infinite, it doesn’t work that way. There’s no meaningful way to assign a numeric value to the ratio of infinite values and so z contains a NaN. (You’d have to know “how they got there” so you could take limits.) So if you print z you’d see nan or 1.#IND depending on your version of Python and your operating system.
The way you test for inf and nan values depends on your version of Python. In Python 3.0, you can use the functions math.isinf and math.isnan respectively. Earlier versions of Python do not have these functions. However, the SciPy library has corresponding functions scipy.isinf and scipy.isnan.
What if you want to deliberately create an inf or a nan? In Python 3.0, you can use float('inf') or float('nan'). In earlier versions of Python you can use scipy.inf and scipy.nan if you have SciPy installed.
IronPython does not yet support Python 3.0, nor does it support SciPy directly. However, you can use SciPy with IronPython by using Ironclad from Resolver Systems. If you don’t need a general numerical library but just want functions like isinf and isnan you can create your own.
def isnan(x): return type(x) is float and x != x
def isinf(x): inf = 1e5000; return x == inf or x == -inf
The isnan function above looks odd. Why would x != x ever be true? According to the IEEE standard, NaNs don’t equal anything, even each other. (See comments on the function IsFinite here for more explanation.) The isinf function is really a dirty hack but it works.
To wrap things up, we should talk a little about integers in Python. Although Python floating point numbers are essentially C floating point numbers, Python integers are not C integers. Python integers have arbitrary precision, and so we can sometimes avoid problems with overflow by working with integers. For example, if we had defined x as 10**200 in the example above, x would be an integer and so would y = x*x and y would not overflow; a Python integer can hold 10400 with no problem. We’re OK as long as we keep producing integer results, but we could run into trouble if we do anything that produces a non-integer result. For example,
x = 10**200; y = (x + 0.5)*x
would cause y to be inf, and
x = 10**200; y = x*x + 0.5
would throw an OverflowError exception.
Related posts