The approach to cancer research presented here sounds really exciting.
Watch on TED.com (link rotted)
The approach to cancer research presented here sounds really exciting.
Watch on TED.com (link rotted)
This morning at church a woman said she was running late because of a software issue. Her alarm clock was manufactured before the US changed the end date of daylight saving time. Her clock “fell back” an hour because daylight saving time would have ended today had the law not changed.
Here are a few thoughts about what went wrong and how it might have been prevented.
Related post: Universal time
“Of course, education has always aimed to be useful. The question has been, and continues to be, useful to what end?” — Richard Gamble
People who write Python choose to write Python.
I don’t hear people say “I use Python at work because I have to, but I’d rather be writing Java.” But often I do hear people say they’d like to use Python if their job would allow it. There must be someone out there writing Python who would rather not, but I think that’s more common with other languages.
My point isn’t that everyone loves Python, but rather that those who don’t care for Python simply don’t write it.
Since Python isn’t a common choice for enterprise software projects, it can resist the pressure to be all things to all people. Having a “Benevolent Dictator for Life” also helps Python maintain conceptual integrity. Python is popular enough to have a critical mass of users, but not so popular that it is under pressure to lose its uniqueness.
I don’t know much about the Ruby world, but I wonder whether the increasing popularity of Ruby for web development has created pressure for Ruby to compromise its original philosophy. And I wonder whether Ruby’s creator Yukihiro Matsumoto has “dictatorial” control over his language analogous to the control Guido van Rossum has over Python.
Joseph Fourier is perhaps best known for his work studying heat conduction. He developed what we now call Fourier series as part of this work.
I recently learned that Fourier had a personal problem with heat.
Even though Fourier conducted foundational work on heat transfer, he was never good at regulating his own heat. He was always so cold, even in the summer, that he wore several large overcoats.
Source: The Physics Book
Here’s an elegant proof from Paul Erdős that there are infinitely many primes. It also does more, giving a lower bound on π(N), the number of primes less than N.
First, note that every integer n can be written as a product n = r s2 where r and s are integers and r is square-free, i.e. not divisible by the square of any integer. To see this, let s2 be the largest square dividing n and set r = n / s2.
Next we over-estimate how many r s2 factorizations there are less than or equal to N.
How many square-free numbers are there less than or equal to N? Every such number corresponds to a product of distinct primes each less than or equal to N. There are π(N) such primes, and so there are at most 2π(N) square-free numbers less than or equal to N. (The number of subsets of a set with m elements is 2m.)
How many squares are there less than N? No more than √N because if s > √N then s2 > N.
So if we factor every number ≤ N into the form r s2 there are at most 2π(N) possibilities for r and at most √N possibilities for s. This means
2π(N) √N ≥ N
Now divide both sides of this inequality by √N and take logarithms. This shows that
π(N) ≥ log(N) / log 4
The right side is unbounded as N increases, so the left side must be unbounded too, i.e. there are infinitely many primes.
Euclid had a simpler proof that there are infinitely many primes. But unlike Euclid, Erdős gives a lower bound on π(N).
Source: Not Always Buried Deep
As I write this, word has it that John McCarthy passed away yesterday. Tech Crunch is reporting this as fact, citing Hacker News, which in turn cites a single tweet as the ultimate source. So the only authority we have, for now, is one person on Twitter, and we don’t know what relation she has to McCarthy.
[Update: More recent comments on Hacker News corroborate the story. Also, the twitterer cited above, Wendy Grossman, said McCarthy’s daughter called her.]
I also have an unsubstantiated story about John McCarthy. I believe I read the following some time ago, but I cannot remember where. If you know of a reference, please let me know. [Update 2: Thanks to Leandro Penz for leaving a link to an article by Paul Graham in the comments below.]
As I recall, McCarthy invented Lisp to be a purely theoretical language, something akin to lambda calculus. When his graduate student Steve Russell spoke of implementing Lisp, McCarthy objected that he didn’t intend Lisp to actually run on a physical computer. Russell then implemented a Lisp interpreter and showed it to McCarthy.
Steve Russell is an unsung hero who deserves some of the credit for Lisp being an actual programming language and not merely a theoretical construct. This does not diminish McCarthy’s achievement, but it does mean that someone else also deserves recognition.
The idea of software maintenance sounds absurd. Why do you have to maintain software? Do the bits try to sneak off the disk so that someone has to put them back?
Software doesn’t change, but the world changes out from under it.
People often perceive these changes as changes to the software, like someone standing on a dock, eyes fixed on a ship, who feels the dock is moving. We speak of software as if it were some mechanical think that physically wears out. Of course it isn’t, but the effect may be the same.
Some photos from the table next to me at lunch today. Alas, poor Yorick did enjoy a good burrito.




Related post: Not exactly rocket science
Suppose you take factorials of a lot of numbers and look at the leading digit of each result. You could argue that there’s no apparent reason that any digit would be more common than any other, so you’d expect each of the digits 1 through 9 would come up 1/9 of the time. Sounds plausible, but it’s wrong.
The leading digits of factorials follow Benford’s law as described in the previous post. In fact, factorials follow Benford’s law even better than physical constants do. Here’s a graph of the leading digits of the factorials of 1 through 500.
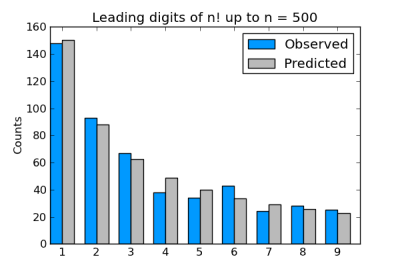
In the remainder of this post, I’ll explain why Benford’s law should apply to factorials, make an aside on statistics, and point out an interesting feature of the Python code used to generate the chart above.
Here’s a hand-waving explanation. One way to justify Benford’s law is to say that physical constants are uniformly distributed, but on a logarithmic scale. The same is true for factorials, and it’s easier to see why.
The leading digits of the logarithms depend on their logarithms in base 10. The gamma function extends the factorial function and it is log-convex. The logarithm of the gamma function is fairly flat (see plot here), and so the leading digits of the log-gamma function applied to integers are uniformly distributed on a logarithmic scale. (I’ve mixed logs base 10 and natural logs here, but that doesn’t matter. All logarithms are the same up to a multiplicative constant. So if a plot is nearly linear on a log10 scale, it’s nearly linear on a natural log scale.)
Update: Graham gives a link in the comments below to a paper proving that factorials satisfy Benford’s law exactly in the limit.
This example brings up an important principle in statistics. Some say that if you don’t have a reason to assume anything else, use a uniform distribution. For example, some say that a uniform prior is the ideal uninformative prior for Bayesian statistics. But you have to ask “Uniform on what scale?” It turns out that the leading digits of physical constants and factorials are indeed uniformly distributed, but on a logarithmic scale.
I used nearly the same code to produce the chart above as I used in its counterpart in the previous post. However, one thing had to change: I couldn’t compute the leading digits of the factorials the same way. Python has extended precision integers, so I can compute 500! factorial without overflowing. Using floating point numbers, I could only go up to 170!. But when I used my previous code to find the leading digit, it first tried to apply log10 to an integer larger than the largest representable floating point number and failed. Converting numbers such as 500! to floating point numbers will overflow. (See Floating point numbers are a leaky abstraction.)
The solution was to find the leading digit using only integer operations.
def leading_digit_int(n):
while n > 9:
n = n/10
return n
This code works fine for numbers like 500! or even larger.