Ramanujan posed the following puzzle to Journal of Indian Mathematical Society. What is the value of the following?

He waited over six months, and when nobody replied he gave his solution. The result is simply 3.
Now suppose you didn’t know an algebraic proof and wanted to evaluate the expression numerically. The code below will evaluate Ramanujan’s expression down to n levels.
def f(n):
t = 1.0
for k in range(n, 1, -1):
t = sqrt(k*t + 1)
return t
(The range function above produces the sequence n, n-1, … 2.)
The sequence of f(n) values converges rapidly to 3 as the plot below shows.
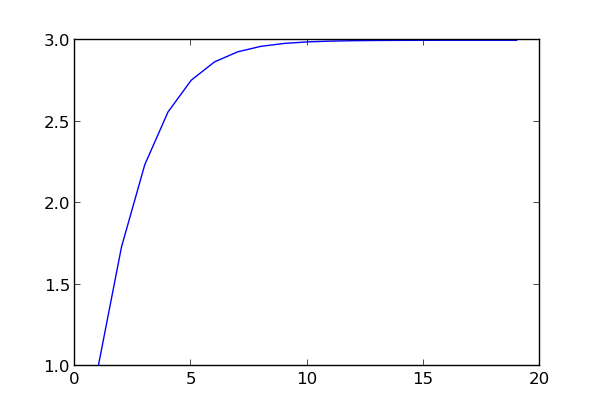
The code above evaluates the expression from the inside out, and so you need to know where you’re going to stop before you start. I don’t see how to write a different algorithm that would let you compute f(n+1) taking advantage of having computed f(n). Do you? Can you think of a way to evaluate f(1), f(2), f(3), … f(N) in less than O(N2) time? Will your algorithm if some or all of the numbers in Ramanujan’s expression change?



{kind=link}
{kind=link}