When I took my first abstract algebra course, we had a homework question about subgroups. Someone in the class whined that the professor hadn’t told us yet what a subgroup was. My immediate thought was “I bet you could guess. Sub things are all the same. A sub-X is an X contained inside another X. Subset, subspace, subgroup, … They’re all the same.”
My initial reaction was right in that all sub-things are analogous. A subspace is a subset of a vector space that is a vector space in its own right, etc. But there are some hairs that are occasionally worth splitting.
If A is a sub-thing of a thing B, and a is an element of A, sometimes it’s useful to distinguish whether we’re thinking of a as an element of A or whether we’re thinking of a as an element of B. For example, the real numbers are contained in the complex numbers, and when we say -3 has no square root, we implicitly mean -3 as a real number. But if we speak of -3 in complex analysis, say as the location of a pole, we’re thinking of -3 as a complex number, a particular location in the complex plane.
This may all seem pedantic, and it may be, depending on context. But in complicated situations, it can help to make fine distinctions explicit. Novices are unaware of fine distinctions, and sophomores love to point them out, but experts know how to adjust the level of rigor to the appropriate level for a given discussion.
If we want a general theory of sub-things that spans multiple areas of math, we have to use category theory. That’s what category theory is for, codifying patterns that occur across various contexts.
But it seems we’re blocked from the beginning since objects in category theory are black boxes. You cannot speak of parts of an object, so you can’t speak of a subgroup as being a group whose elements belong to another group. You can’t speak of elements at all using the language of category theory.
The only tool at your disposal in category theory is functions. Or to be more precise, morphisms, things that act like functions but might not actually be functions.
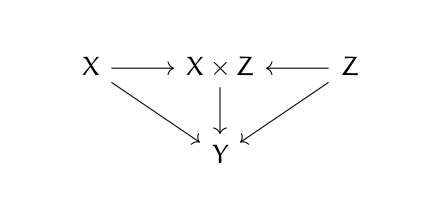
What kind of function acts like a subset? Inclusion maps. If A is a subset of B, then there’s a function mapping A into B that sends every point to itself. Going back to the discussion above, an inclusion map is a function that takes a as a member of A to a as a member of B.
Inclusion maps are one-to-one (injective) and so maybe we could use one-to-one functions as our analog of sub-objects.
But saying a function is one-to-one requires looking inside an object and speaking of elements, and that’s not allowed in category theory. And besides, morphisms might not be functions. However, we can say what it means for a morphism to act like a one-to-one function. The categorical counterpart to an injective function is a monomorphism, sometimes just shortened to a “mono.” A subobject of a an object B is a an object A along with a monomorphism from A to B. [1]
By moving from injective functions to monomorphisms we’ve gained something and we’ve lost something.
We’ve gained the notion of preserving structure. For example, a subspace of a vector space isn’t just any subset of a vector space, it’s a linear subspace. In the context of linear algebra we could identify a linear subspace with an injective linear map. When morphisms are functions, they’re not arbitrary functions, but structure-preserving functions, such as linear transformations on linear spaces and continuous functions on topological spaces.
But when we move from subsets to monomorphisms we lose some specificity. If we have a monomorphism from A into B, the object A is only unique up to isomorphism. Everything in category theory is only determined up to isomorphism.
In one way this may be no loss. When we say, for example, that one group is a subgroup of another, maybe all we care about is the structure of the subgroup itself and we don’t care to distinguish isomorphic versions of the subgroup.
But if we’re talking about a manifold M being a submanifold N, we may care which submanifold it is. For example, a circle can be embedded in a torus (doughnut), and it may matter a great deal how we embed it.
If all subobjects are isomorphic, how can we tell them apart? That’s where subobject classifiers come in, a topic I may write about in the future.
More category theory posts
- One diagram, two completely different meanings
- Examples of universal properties
- Category theory for programmers made a little easier
[1] For more on subobjects, see Robert Goldblatt’s book Topoi: The Categorical Analysis of Logic.