The question came up on StackOverflow this morning how to compute the error function erf(x) in Python. The standard answer for how to compute anything numerical in Python is “Look in SciPy.” However, this person didn’t want to take on the dependence on SciPy. I’ve seen variations on this question come up in several different contexts lately, including questions about computing the normal distribution function, so I thought I’d write up a solution.
Here’s a Python implementation of erf(x) based on formula 7.1.26 from A&S. The maximum error is below 1.5 × 10-7.
import math
def erf(x):
# constants
a1 = 0.254829592
a2 = -0.284496736
a3 = 1.421413741
a4 = -1.453152027
a5 = 1.061405429
p = 0.3275911
# Save the sign of x
sign = 1
if x < 0:
sign = -1
x = abs(x)
# A & S 7.1.26
t = 1.0/(1.0 + p*x)
y = 1.0 - (((((a5*t + a4)*t) + a3)*t + a2)*t + a1)*t*math.exp(-x*x)
return sign*y
This problem is typical in two ways: A&S has a solution, and you’ve got to know a little background before you can use it.
The formula given in A&S is only good for x ≥ 0. That’s no problem if you know that the error function is an odd function, i.e. erf(-x) = -erf(x). But if you’re an engineer who has never heard of the error function but needs to use it, it may take a while to figure out how to handle negative inputs.
One other thing that someone just picking up A&S might not know is the best way to evaluate polynomials. The formula appears as 1 – (a1t1 + a2t2 + a3t3 + a4t4 + a5t5)exp(-x2), which is absolutely correct. But directly evaluating an nth order polynomial takes O(n2) operations, while the factorization used in the code above uses O(n) operations. This technique is known as Horner’s method.




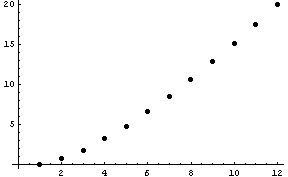 The points nearly fall on a straight line, but if you look closely, the points bend upward slightly. If you have trouble seeing this, imagine a line connecting the first and last dot. This line would lie above the dots in between. This suggests that a function whose graph passes through all the dots should be convex.
The points nearly fall on a straight line, but if you look closely, the points bend upward slightly. If you have trouble seeing this, imagine a line connecting the first and last dot. This line would lie above the dots in between. This suggests that a function whose graph passes through all the dots should be convex.