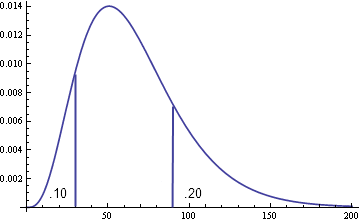
The doctor says 10% of patients respond within 30 days of treatment and 80% respond within 90 days of treatment. Now go turn that into a probability distribution. That’s a common task in Bayesian statistics, capturing expert opinion in a mathematical form to create a prior distribution.
Things would be easier if you could ask subject matter experts to express their opinions in statistical terms. You could ask “If you were to represent your belief as a gamma distribution, what would the shape and scale parameters be?” But that’s ridiculous. Even if they understood the question, it’s unlikely they’d give an accurate answer. It’s easier to think in terms of percentiles.
Asking for mean and variance are not much better than asking for shape and scale, especially for a non-symmetric distribution such as a survival curve. Anyone who knows what variance is probably thinks about it in terms of a normal distribution. Asking for mean and variance encourages someone to think about a symmetric distribution.
So once you have specified a couple percentiles, such as the example this post started with, can you find parameters that meet these requirements? If you can’t meet both requirements, how close can you come to satisfying them? Does it depend on how far apart the percentiles are? The answers to these questions depend on the distribution family. Obviously you can’t satisfy two requirements with a one-parameter distribution in general. If you have two requirements and two parameters, at least it’s feasible that both can be satisfied.
If you have a random variable X whose distribution depends on two parameters, when can you find parameter values so that Prob(X ≤ x1) = p1 and Prob(X ≤ x2) = p2? For starters, if x1 is less than x2 then p1 must be less than p2. For example, the probability of a variable being less than 5 cannot be bigger than the probability of being less than 6. For some common distributions, the only requirement is this requirement that the x‘s and p‘s be in a consistent order.
For a location-scale family, such as the normal or Cauchy distributions, you can always find a location and scale parameter to satisfy two percentile conditions. In fact, there’s a simple expression for the parameters. The location parameter is given by

and the scale parameter is given by

where F(x) is the CDF of the distribution representative with location 0 and scale 1.
The shape and scale parameters of a Weibull distribution can also be found in closed form. For a gamma distribution, parameters to satisfy the percentile requirements always exist. The parameters are easy to determine numerically but there is no simple expression for them.
For more details, see Determining distribution parameters from quantiles. See also the ParameterSolver software.
Update: I posted an article on CodeProject with Python code for computing the parameters described here.

