In applications you often want to take the maximum of two numbers. But the simple function
f(x, y) = max(x, y)
can be difficult to work with because it has sharp corners. Sometimes you want an alternative that sands down the sharp edges of the maximum function. One such alternative is the soft maximum. Here are some questions this post will answer.
- What exactly is a soft maximum and why is it called that?
- How is it related to the maximum function?
- In what sense does the maximum have “sharp edges”?
- How does the soft maximum round these edges?
- What are the advantages to the soft maximum?
- Can you control the “softness”?
I’ll call the original maximum the “hard” maximum to make it easier to compare to the soft maximum.
The soft maximum of two variables is the function
g(x, y) = log( exp(x) + exp(y) ).
This can be extended to more than two variables by taking
g(x1, x2, …, xn) = log( exp(x1) + exp(x2) + … + exp(xn) ).
The soft maximum approximates the hard maximum. Why? If x is a little bigger than y, exp(x) will be a lot bigger than exp(y). That is, exponentiation exaggerates the differences between x and y. If x is significantly bigger than y, exp(x) will be so much bigger than exp(y) that exp(x) + exp(y) will essentially equal exp(x) and the soft maximum will be approximately log( exp(x) ) = x, the hard maximum. Here’s an example. Suppose you have three numbers: -2, 3, 8. Obviously the maximum is 8. The soft maximum is 8.007.
The soft maximum approximates the hard maximum but it also rounds off the corners. Let’s look at some graphs that show what these corners are and how the soft maximum softens them.
Here are 3-D plots of the hard maximum f(x, y) and the soft maximum g(x, y). First the hard maximum:
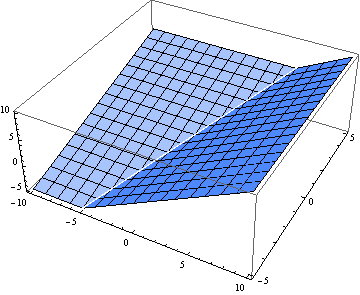
Now the soft maximum:
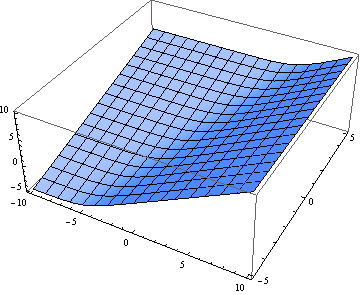
Next we look at a particular slice through the graph. Here’s the view as we walk along the line y = 1. First the hard maximum:
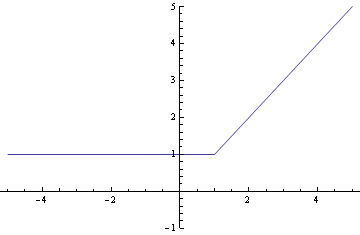
And now the soft maximum:
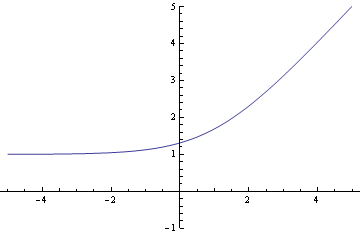
Finally, here are the contour plots. First the hard maximum:
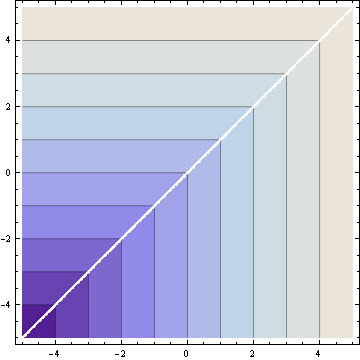
And now the soft maximum:
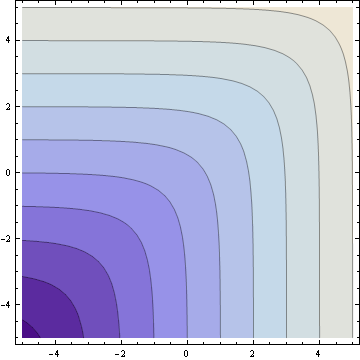
The soft maximum approximates the hard maximum and is a convex function just like the hard maximum. But the soft maximum is smooth. It has no sudden changes in direction and can be differentiated as many times as you like. These properties make it easy for convex optimization algorithms to work with the soft maximum. In fact, the function may have been invented for optimization; that’s where I first heard of it.
Notice that the accuracy of the soft maximum approximation depends on scale. If you multiply x and y by a large constant, the soft maximum will be closer to the hard maximum. For example, g(1, 2) = 2.31, but g(10, 20) = 20.00004. This suggests you could control the “hardness” of the soft maximum by generalizing the soft maximum to depend on a parameter k.
g(x, y; k) = log( exp(kx) + exp(ky) ) / k
You can make the soft maximum as close to the hard maximum as you like by making k large enough. For every value of k the soft maximum is differentiable, but the size of the derivatives increase as k increases. In the limit the derivative becomes infinite as the soft maximum converges to the hard maximum.
Update: See How to compute the soft maximum.





