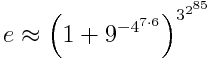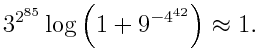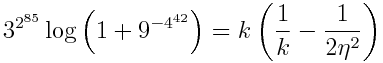While I was in Europe, someone commented to me that Americans are the most fearless and the most fearful people on Earth. We put men on the moon, and we walk around with hand sanitizer. We start bold business ventures and have ridiculously cautious safety regulations. We’re the home of cowboys and helicopter parents.
One response I had was that it’s not necessarily the same people who are being so bold and so timid. There’s a tension between the risk-tolerant and the risk-averse in America. The former are free to be bold in the private sector while the latter outvote them in the public sector.
Another explanation might be that an individual can be fearless and fearful about different things. Someone may be willing to risk millions of dollars but not be willing to risk eating unpasteurized food. There may be some sort of general risk homeostasis, though I imagine people willing to take risks in one area are often more willing to take risks in another area.