This page presents C++ code for computing the inverse of the normal (Gaussian) CDF. The emphasis, however, is on the process of writing the code. The discussion points out some of the things people are expected to pick up along the way but may never have been taught explicitly.
This page develops the code in the spirit of a literate program. The code will be developed in small pieces, then the final code presented at the bottom of the page. This page is not actually a literate program but it strives to serve the same purpose.
Problem statement
Basic solution
Numerical issues
Take away
Complete code
Problem statement
We need software to compute the inverse of the normal CDF (cumulative density function). That is, given a probability p, compute x such that Prob(Z < x) = p where Z is a standard normal (Gaussian) random variable. We don’t need high precision; three or four decimal places will suffice.
Basic solution
We can look up an algorithm that will essentially compute what we need. But there is some work to do in order to turn the algorithm we find into working code.
The first place to look for approximations to statistical functions is Abramowitz and Stegun or A&S at it is fondly known. Formula 26.2.23 from A&S is given below.
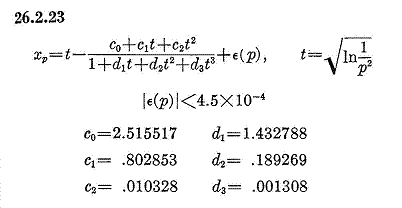
A&S describes the formula above as a “rational approximation for xp where Q(xp) = p.” In A&S notation, Q is the CCDF (complementary cumulative distribution function) for a standard normal. Also, A&S says that the approximation is good for 0 < p ≤ 0.5. The reported absolute error in the approximation is less than 4 × 10-4, so the accuracy is sufficient. We have two immediate problems. First, we want to invert the CDF, not the CCDF. Second, we need an algorithm for 0 < p < 1 and not just for p < 0.5.
Let F(x) be the CDF of a standard normal and let G(x) be the corresponding CCDF. We want to compute the inverse CDF, F-1(p), but A & S gives us a way to compute G-1(p). Now for all x, F(x) + G(x) = 1. So if G(x) = 1-p then F(x) = p. That means that
F-1(p) = G-1(1-p)
and so our first problem is solved. If p ≥ 0.5, 1 – p ≤ 0.5 and so the approximation from A&S applies. But what if p < 0.5?
Since the standard normal distribution is symmetric about zero, the probability of being greater than x is the same as the probability of being less than –x. That is, G(x) = p if and only if F(-x) = p. So x = G-1(p) if and only if x = –F-1(p). Thus
F-1(p) = –G-1(p).
We can use the above formula to compute F-1(p) for p < 0.5.
Numerical issues
The first step in applying the formula from A&S is to transform p into sqrt(-2.0*log(p)). So for p < 0.5 we compute t = sqrt(-2.0*log(p)) and evaluate the ratio of polynomials for approximating G-1(p) and flip the sign of the result. For p ≥ 0.5, we compute t = sqrt(-2.0*log(1-p)). If RationalApproximation is the function to evaluate the ratio of polynomials, the code for computing F-1 starts as follows.
if (p < 0.5)
{
// F^-1(p) = - G^-1(p)
return -RationalApproximation( sqrt(-2.0*log(p)) );
}
else
{
// F^-1(p) = G^-1(1-p)
return RationalApproximation( sqrt(-2.0*log(1-p)) );
}
Writing the code for RationalApproximation is easy. However, we introduce a technique along the way. We could evaluate a polynomial of the form a + bx +cx2 + dx3 by computing
a + b*x + c*x*x + d*x*x*x
but we could save a few cycles using Horner’s method to evaluate the polynomial as
((d*x + c)*x + b)*x + a.
The time savings isn’t much for a low-order polynomial. On the other hand, Horner’s rule is easy to apply so it’s a good habit to always use it to evaluate polynomials. It could make a difference in evaluating high-order polynomials in the inner loop of a program.
Using Horner’s rule, our code for RationalApproximation is as follows.
double RationalApproximation(double t)
{
const double c[] = {2.515517, 0.802853, 0.010328};
const double d[] = {1.432788, 0.189269, 0.001308};
return t - ((c[2]*t + c[1])*t + c[0]) /
(((d[2]*t + d[1])*t + d[0])*t + 1.0);
}
Take away
Here’s a summary of a couple things this code illustrates.
- Abramowitz and Stegun is a good place to start when looking for information about statistical functions.
- Horner’s method of evaluating polynomials is simple and runs faster than the most direct approach.
If you want to learn more about literate programming, we recommend Donald Knuth’s book Literate Programming.
Complete code
Here we present the final code with some input validation added. We also include some code to test/demonstrate the code for evaluating F-1.= – G^-1(p)
#include <cmath>
#include <iomanip>
#include <iostream>
#include <sstream>
#include <stdexcept>
double LogOnePlusX(double x);
double NormalCDFInverse(double p);
double RationalApproximation(double t);
void demo();
double RationalApproximation(double t)
{
// Abramowitz and Stegun formula 26.2.23.
// The absolute value of the error should be less than 4.5 e-4.
double c[] = {2.515517, 0.802853, 0.010328};
double d[] = {1.432788, 0.189269, 0.001308};
return t - ((c[2]*t + c[1])*t + c[0]) /
(((d[2]*t + d[1])*t + d[0])*t + 1.0);
}
double NormalCDFInverse(double p)
{
if (p <= 0.0 || p >= 1.0)
{
std::stringstream os;
os << "Invalid input argument (" << p
<< "); must be larger than 0 but less than 1.";
throw std::invalid_argument( os.str() );
}
// See article above for explanation of this section.
if (p < 0.5)
{
// F^-1(p) = - G^-1(p)
return -RationalApproximation( sqrt(-2.0*log(p)) );
}
else
{
// F^-1(p) = G^-1(1-p)
return RationalApproximation( sqrt(-2.0*log(1-p)) );
}
}
void demo()
{
std::cout << "\nShow that the NormalCDFInverse function is accurate at \n"
<< "0.05, 0.15, 0.25, ..., 0.95 and at a few extreme values.\n\n";
double p[] =
{
0.0000001,
0.00001,
0.001,
0.05,
0.15,
0.25,
0.35,
0.45,
0.55,
0.65,
0.75,
0.85,
0.95,
0.999,
0.99999,
0.9999999
};
// Exact values computed by Mathematica.
double exact[] =
{
-5.199337582187471,
-4.264890793922602,
-3.090232306167813,
-1.6448536269514729,
-1.0364333894937896,
-0.6744897501960817,
-0.38532046640756773,
-0.12566134685507402,
0.12566134685507402,
0.38532046640756773,
0.6744897501960817,
1.0364333894937896,
1.6448536269514729,
3.090232306167813,
4.264890793922602,
5.199337582187471
};
double maxerror = 0.0;
int numValues = sizeof(p)/sizeof(double);
std::cout << "p, exact CDF inverse, computed CDF inverse, diff\n\n";
std::cout << std::setprecision(7);
for (int i = 0; i < numValues; ++i)
{
double computed = NormalCDFInverse(p[i]);
double error = exact[i] - computed;
std::cout << p[i] << ", " << exact[i] << ", "
<< computed << ", " << error << "\n"; if (fabs(error) > maxerror)
maxerror = fabs(error);
}
std::cout << "\nMaximum error: " << maxerror << "\n\n";
}
int main()
{
demo();
return 0;
}