Regular expressions are very handy, but unfortunately they are implemented at least slightly differently everywhere you use them. These notes survey the implementation of regular expressions in Perl, Python, and Emacs. They are not exhaustive. If I went into every minute detail, I’d have a book rather than a page of notes.
When I say “Python” here, I mean Python’s re module as implemented at the time of writing at the end of 2015. There are other options in Python more compatible with Perl, and rumor has it that these will eventually be merged into the standard Python distribution.
Also, these notes only concern regular expression syntax, not how regular expressions are used. See these notes for a comparison of how to use regular expressions for common tasks like searching and replacing in Perl and Python.
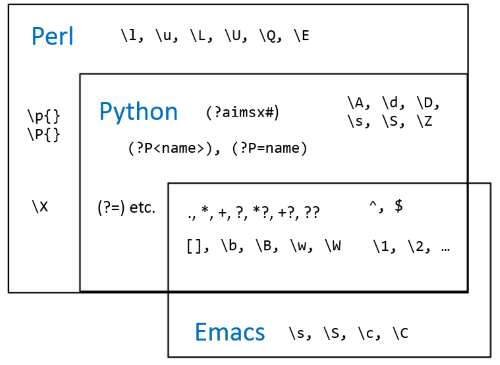
Common features across Emacs, Python, Perl
The most basic regex features are the same in nearly every implementation: wild character ., quantifiers *, +, and ?, anchors ^ and $, character classes inside [], and back references \1, \2, \3 etc.
Recent versions of Emacs support the metacharacters \b for word boundaries, and \B for non-word boundaries, \w for word characters, and \W for non-word characters.
Generally Emacs supports only the oldest features of regular expressions, but it does support the relatively recent innovation of non-greedy quantifiers *?, +?, and ??.
Common features requiring backslashes in Emacs
Alternation is denoted | in Perl and Python, but requires \| in Emacs. Similarly, grouping parentheses must be escaped in Emacs: \( and \). Also, denoting how many times a pattern should match inside curly braces requires extra backslashes in Emacs: \{ and \}.
Another exception to Emacs’ lack of recent features is non-grouping parentheses. However, these parentheses also require backslashes: \(?: … \).
Features unique to Emacs
Syntax classes
Syntax classes begin with \s in Emacs. And as is conventional in regular expressions, the negation of the class uses the corresponding capital \S.
For example, \s. denotes any punctuation character, and \S. denotes any non-punctuation character. Emacs uses \s( for opening delimiters and \s) for closing delimiters, \s< for opening comment characters, \s> for closing comment characters, and has other syntax classes.
Note that since Emacs uses \s and \S to begin syntax classes, it does not use these for whitespace and non-whitespace the way Perl and Python do. Whitespace in Emacs is denoted \s- and non-whitespace \S-.
Character classes
Character classes are similar to syntax classes but begin with \c for positive and \C for negative. These are similar to Unicode properties \p{} and \P{} in Perl.
For example, \cg stands for any Greek character and \Cg for any non-Greek character. Run M-x describe-categories to see more information on character classes.
Features in Python and Perl, not in Emacs
Perl and Python will let you modify a regular expression with (?aimsx). For example, (?i) makes an expression case-insensitive. These modifiers have the same meaning on both languages. Also, both languages let you introduce a comment in a regular expression with (?# … ).
Perl and Python support positive and negative look-around with the same syntax: (?=), (?!), (?<=), and (?<!).
Both languages support the anchors \A and \Z, and the character classes \d and \D, \s and \S.
Both languages let you name a capture with (?P<name>) and reference it with (?P=name). Perl has its own syntax for this in addition to supporting the syntax of Python.
Features in Perl, not in Python
The biggest feature in Perl regular expressions not in Python (i.e. not in Python’s re module at the time of writing) is Unicode character classes \p{} and their negation \P{}.
Perl’s \X is a sort of variation on . for Unicode. Programming Perl describes it this way:
The point is that
\Xmatches one user-visible character (grapheme), even if it takes several programmer-visible characters (code-points) to do so.
A few other features unique to Perl are quoting with \Q and \E, making characters lowercase or title case with \l and \u, or making a sequence of characters lower or uppercase beginning with \L or \U and ending with \E.
There are many other regular expression features unique to Perl, but I’ve highlighted the ones I’m most likely to want to use.