Tux: The advantages of binary formats are immediate and visible. The disadvantages are more subtle and take longer to notice.
Why mess around with LaTeX files, for example, when you can use Microsoft Word? Certainly your first hour in front of Word is more productive than your first our in front of LaTeX. It may be quite a while before you run into issues with licenses, compatibility, strange behavior you cannot debug, a desire to separate presentation from content, etc.
“Plain text” is a usefully vague term, that hides the social conventions and traditions around and behind it. It also hides the fact that plain text as a social convention and tradition has evolved over time.
For example, diff, patch, and merge do things (moderately reasonable things for the most part) with lines. They were implemented responding to previous line useage, but new programming languages and new programming conventions have acknowledged the installed base of existing line-based diff, patch and merge.
To some extent, the point is not binary vs. plain-text, it is “rationalized”, rigid, top-down formats vs. messier, harder to specify formats that respect the history and ecosystem. James Scott has a book called “Seeing like a State” that talks about failures (mostly not software failures) caused by people enforcing a top-down rigidity: http://www.ribbonfarm.com/2010/07/26/a-big-little-idea-called-legibility/
Matt Doar
I think the tools make the difference. Text-based tools have had nearly 50 years of development. Programming languages support text natively. So I have confidence I can do the unexpected with text. More complex formats, some of which are opaque, bind me to specific tools.
John
Johnicholas: Good point. All computer files are binary, including text files. But “text” and “binary” are useful shorthand for collections of characteristics.
Mike
Modern word (docx) is viewable as plain text as is odf files (KOffice, OpenOffice, etc). Not sure about Apple’s Pages software. I can see an argument if you are just considering text on a screen. But once you open up LaTex as an example you are essentially just picking an encoding/convention. What is the difference between an XML format of encoding and LaTex other than your familiarity with it?
John
Mike: That’s a good example of the point Johnicholas was making above. The current Word doc format is XML files zipped together and given a .docx extension. So an unzipped Word document is technically not a binary file, while a zipped LaTeX document technically is.
One difference is transparency. LaTeX files are intended to be human readable, and they are a fairly light-weight markup on content. Someone who doesn’t know LaTeX can read a LaTeX file for its meaning, and could easily find articles or books to learn how to understand it more thoroughly.
Machine-generated XML files are technically human readable, but are not intended for human use. When Microsoft announced the new file formats, they were quick to say that they did not recommend creating or manipulating such files without going through their APIs. If you manually tweak the files anyway, you’re on your own. You may corrupt the file with no error message. (Still, that is an improvement over the old Word format because as a last resort, you can unzip the file and poke around. I don’t remember whether I’ve done that for Word documents, but I have for Excel files.)
heltonbiker
“Why the up part PRIOR to the bottom bump?”
As the talk has been orbiting around, say “txt vs. Word”, I’d say that, the more technically oriented I become, the more ugly the “Word way of doing things” feels to me. Throwing long, sweaty brainwork into a Word document (in a long, tedious, incidental and sweaty way), is just a trap to your future self, until you need it back. With TXT, your stuff is always there to be human OR machine read with any script language you might want.
And if you need rich text, Google Docs is doing GREATLY (oh, and by the way, hard-drive-failure proof)
Matt Doar
My test is to come up with some moderately complex operation such as “change every other instance of a word to a different word” and see how I can do this for 1000 occurrences. That’s where text or simple formats often win
John
heltonbiker: I first used text files because I didn’t know about anything else. I used computers for years before I ever used MS Office, for example.
And just to move the conversation away from word processing, I tried several software applications for managing contacts before I settled on my favorite: a plain text file, an org-mode document edited in Emacs. There’s a top-level node for each letter of the alphabet, and contacts are listed alphabetically as second-level nodes. Below that, there’s no structure.
lens
This brings to mind:
“Me too!” and
“Wisdom is the difference between obvious and correct.”
DavidC
I’m surprised no one has pointed out that most of the content of this post isn’t plain text!
John
A lot of things, like images, are best represented in binary formats, though not quite as many things as I once thought.
Enok
Vector graphics are best in plain text too!
MikeA
“All computer files are binary”? That depends.
I can get pedantic in two different directions on that one. The first computer I ever used was a decimal/charcter machine. The addresses in instructions, as well as the data, used BCD (Binary Coded Decimal, the 8421 code we are familiar with, although I’ve been told that within the ALU it sometimes used 5421). Even the (machine language, not assembler) op-codes “made sense” as text. e.g. ‘M’ for Move, ‘A’ for add, ‘B’ for branch, etc. Even the non-obvious ones made a certain sense, like ‘.’ for HALT. Sure, these characters were stored in binary, but that’s the other “not always”. If you use MLC flash (any cheap flash media), it probably stores those “binary” files as base 4 or 8, and if you send them over a LAN faster than 10BaseT, or a dialup modem (dinosaur alert) over 600bps, yep, non-binary.
None of which detracts from the awesomeness of those particular “binary” formats that can be understood without knowing the exact version of the software that wrote them and having a signed NDA.
There are so many sides to this question, and I struggle with the dichotomy every day. Being as brief as I can:
* Ascii is the ultimate interchange format. Email & HTTP are embedded in it
* UNIX text-smashing tools (sed, awk, perl) are fundamental time-savers
* We _still_ write virtually all code in plain text
* The WYSIWYG fiction is a mixed blessing
* The tenet that “users are too dumb to deal with text encodings” is false and waning
I think, ultimately, that belief in WYSIWYG and user dumbness underlay the entire Office business proposition. It was close enough to the actual truth, which is “users want to SEE what they’re going to get,” YSWYGTG, that the business succeeded — madly — reinforcing the belief. But now that we have tools that let you SEE your TeX results instantly, or coding IDEs that do instant lookups and suggestions, even Bret-Victor types of environments (or Mathematica or even R) where you SEE results NOW, the benefits of plain text are surging back. Moore’s Law and visionary devs help.
Still, every day, I need to exchange Word and PowerPoint and Excel docs with other people, so I will be kept “in the box” for the foreseeable future.
Shae Erisson
I considered posting a reply in XER encoded ASN.1, but realized the ITU specifications describing the ASN.1 standard I’m using are prohibitively expensive.
But seriously, the first time I had to implement a reader for an ASN.1 format (RFC 3161), I became firmly convinced that plain text is the sanest format for most everything.
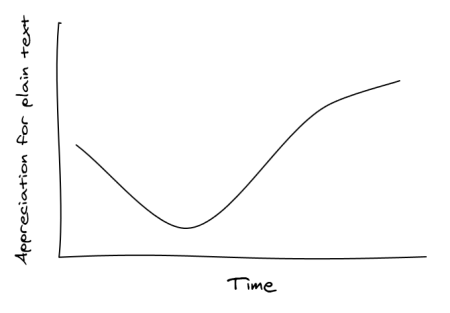
What was the reason for the bottom bump?
Tux: The advantages of binary formats are immediate and visible. The disadvantages are more subtle and take longer to notice.
Why mess around with LaTeX files, for example, when you can use Microsoft Word? Certainly your first hour in front of Word is more productive than your first our in front of LaTeX. It may be quite a while before you run into issues with licenses, compatibility, strange behavior you cannot debug, a desire to separate presentation from content, etc.
“Plain text” is a usefully vague term, that hides the social conventions and traditions around and behind it. It also hides the fact that plain text as a social convention and tradition has evolved over time.
For example, diff, patch, and merge do things (moderately reasonable things for the most part) with lines. They were implemented responding to previous line useage, but new programming languages and new programming conventions have acknowledged the installed base of existing line-based diff, patch and merge.
To some extent, the point is not binary vs. plain-text, it is “rationalized”, rigid, top-down formats vs. messier, harder to specify formats that respect the history and ecosystem. James Scott has a book called “Seeing like a State” that talks about failures (mostly not software failures) caused by people enforcing a top-down rigidity: http://www.ribbonfarm.com/2010/07/26/a-big-little-idea-called-legibility/
I think the tools make the difference. Text-based tools have had nearly 50 years of development. Programming languages support text natively. So I have confidence I can do the unexpected with text. More complex formats, some of which are opaque, bind me to specific tools.
Johnicholas: Good point. All computer files are binary, including text files. But “text” and “binary” are useful shorthand for collections of characteristics.
Modern word (docx) is viewable as plain text as is odf files (KOffice, OpenOffice, etc). Not sure about Apple’s Pages software. I can see an argument if you are just considering text on a screen. But once you open up LaTex as an example you are essentially just picking an encoding/convention. What is the difference between an XML format of encoding and LaTex other than your familiarity with it?
Mike: That’s a good example of the point Johnicholas was making above. The current Word doc format is XML files zipped together and given a .docx extension. So an unzipped Word document is technically not a binary file, while a zipped LaTeX document technically is.
One difference is transparency. LaTeX files are intended to be human readable, and they are a fairly light-weight markup on content. Someone who doesn’t know LaTeX can read a LaTeX file for its meaning, and could easily find articles or books to learn how to understand it more thoroughly.
Machine-generated XML files are technically human readable, but are not intended for human use. When Microsoft announced the new file formats, they were quick to say that they did not recommend creating or manipulating such files without going through their APIs. If you manually tweak the files anyway, you’re on your own. You may corrupt the file with no error message. (Still, that is an improvement over the old Word format because as a last resort, you can unzip the file and poke around. I don’t remember whether I’ve done that for Word documents, but I have for Excel files.)
“Why the up part PRIOR to the bottom bump?”
As the talk has been orbiting around, say “txt vs. Word”, I’d say that, the more technically oriented I become, the more ugly the “Word way of doing things” feels to me. Throwing long, sweaty brainwork into a Word document (in a long, tedious, incidental and sweaty way), is just a trap to your future self, until you need it back. With TXT, your stuff is always there to be human OR machine read with any script language you might want.
And if you need rich text, Google Docs is doing GREATLY (oh, and by the way, hard-drive-failure proof)
My test is to come up with some moderately complex operation such as “change every other instance of a word to a different word” and see how I can do this for 1000 occurrences. That’s where text or simple formats often win
heltonbiker: I first used text files because I didn’t know about anything else. I used computers for years before I ever used MS Office, for example.
And just to move the conversation away from word processing, I tried several software applications for managing contacts before I settled on my favorite: a plain text file, an org-mode document edited in Emacs. There’s a top-level node for each letter of the alphabet, and contacts are listed alphabetically as second-level nodes. Below that, there’s no structure.
This brings to mind:
“Me too!” and
“Wisdom is the difference between obvious and correct.”
I’m surprised no one has pointed out that most of the content of this post isn’t plain text!
A lot of things, like images, are best represented in binary formats, though not quite as many things as I once thought.
Vector graphics are best in plain text too!
“All computer files are binary”? That depends.
I can get pedantic in two different directions on that one. The first computer I ever used was a decimal/charcter machine. The addresses in instructions, as well as the data, used BCD (Binary Coded Decimal, the 8421 code we are familiar with, although I’ve been told that within the ALU it sometimes used 5421). Even the (machine language, not assembler) op-codes “made sense” as text. e.g. ‘M’ for Move, ‘A’ for add, ‘B’ for branch, etc. Even the non-obvious ones made a certain sense, like ‘.’ for HALT. Sure, these characters were stored in binary, but that’s the other “not always”. If you use MLC flash (any cheap flash media), it probably stores those “binary” files as base 4 or 8, and if you send them over a LAN faster than 10BaseT, or a dialup modem (dinosaur alert) over 600bps, yep, non-binary.
None of which detracts from the awesomeness of those particular “binary” formats that can be understood without knowing the exact version of the software that wrote them and having a signed NDA.
There are so many sides to this question, and I struggle with the dichotomy every day. Being as brief as I can:
* Ascii is the ultimate interchange format. Email & HTTP are embedded in it
* UNIX text-smashing tools (sed, awk, perl) are fundamental time-savers
* We _still_ write virtually all code in plain text
* The WYSIWYG fiction is a mixed blessing
* The tenet that “users are too dumb to deal with text encodings” is false and waning
I think, ultimately, that belief in WYSIWYG and user dumbness underlay the entire Office business proposition. It was close enough to the actual truth, which is “users want to SEE what they’re going to get,” YSWYGTG, that the business succeeded — madly — reinforcing the belief. But now that we have tools that let you SEE your TeX results instantly, or coding IDEs that do instant lookups and suggestions, even Bret-Victor types of environments (or Mathematica or even R) where you SEE results NOW, the benefits of plain text are surging back. Moore’s Law and visionary devs help.
Still, every day, I need to exchange Word and PowerPoint and Excel docs with other people, so I will be kept “in the box” for the foreseeable future.
I considered posting a reply in XER encoded ASN.1, but realized the ITU specifications describing the ASN.1 standard I’m using are prohibitively expensive.
But seriously, the first time I had to implement a reader for an ASN.1 format (RFC 3161), I became firmly convinced that plain text is the sanest format for most everything.