Prolog is the original logic programming language. The name comes from programming in logic. More specifically, the name comes from programmation en logique because the inventor of the language, Philippe Roussel, is French.
Prolog has its advantages and disadvantages. One of the advantages is that the language represents logical problems directly. One of the disadvantages is that the syntax can be quirky. But if an LLM is writing the code, or at least helping to write the code, the syntax doesn’t matter so much.
I wanted to see how well Claude (Sonnet 4.6, medium effort) could solve a chess puzzle by Martin Gardner that I wrote about a little over a year ago. I chose a relatively obscure problem rather than something like the Eight Queens puzzle because an LLM could simply quote one of countless articles on the puzzle.
The puzzle
As I stated in the post last year, the task is to place two rooks, two bishops, and two knights on a 4 by 4 chessboard so that no piece attacks any other.
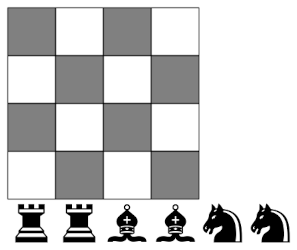
There are two basic solutions, twelve if you count rotations and reflections as different solutions.
Prolog results
Claude wrote an SWI-Prolog program that I ran with
swipl -g "run, halt" chess_placement.pl
and it gave the following output.
Total solutions (raw): 12
Solutions up to D4 symmetry: 2
Solutions up to D4 symmetry: 2
Solution 1:
B . . N
N . . B
. R . .
. . R .
Solution 2:
. B N .
. . . R
R . . .
. N B .
Claude made a nice image of the solutions.

Note that you can make eight variations of the first solution by a combination of rotations and flips. There are only four variations of the second solution because two rotations put you back where you started.
Prolog source
Here’s the Prolog code that Claude generated.
% ============================================================
% Non-attacking placement of 2 Rooks, 2 Bishops, 2 Knights
% on a 4x4 chessboard
%
% Run with SWI-Prolog:
% swipl -g "run, halt" chess_placement.pl
%
% Or interactively:
% swipl chess_placement.pl
% ?- run.
% ?- count_solutions(N).
% ?- count_unique(N).
% ============================================================
:- use_module(library(lists)).
% ---- Board squares: (Row, Col) with Row, Col in 0..3 ----------------
square(R, C) :- member(R, [0,1,2,3]), member(C, [0,1,2,3]).
% ---- Attack predicates ----------------------------------------------
rook_attacks(R,_,R,_). % same row
rook_attacks(_,C,_,C). % same column
bishop_attacks(R1,C1,R2,C2) :-
DR is abs(R1-R2), DC is abs(C1-C2),
DR =:= DC, DR > 0.
knight_attacks(R1,C1,R2,C2) :-
DR is abs(R1-R2), DC is abs(C1-C2),
( DR =:= 1, DC =:= 2 ; DR =:= 2, DC =:= 1 ).
% attacks(+Type1, +R1, +C1, +Type2, +R2, +C2)
% True if either piece threatens the other's square.
attacks(rook, R1,C1, _, R2,C2) :- rook_attacks(R1,C1,R2,C2).
attacks(_, R1,C1, rook, R2,C2) :- rook_attacks(R1,C1,R2,C2).
attacks(bishop, R1,C1, _, R2,C2) :- bishop_attacks(R1,C1,R2,C2).
attacks(_, R1,C1, bishop,R2,C2) :- bishop_attacks(R1,C1,R2,C2).
attacks(knight, R1,C1, _, R2,C2) :- knight_attacks(R1,C1,R2,C2).
attacks(_, R1,C1, knight,R2,C2) :- knight_attacks(R1,C1,R2,C2).
% ---- All pairs safe -------------------------------------------------
% Check all unordered pairs in a list.
no_attack_pair(_, []).
no_attack_pair(T1-(R1,C1), [T2-(R2,C2)|Rest]) :-
\+ attacks(T1,R1,C1,T2,R2,C2),
no_attack_pair(T1-(R1,C1), Rest).
all_pairs_safe([]).
all_pairs_safe([P|Rest]) :-
no_attack_pair(P, Rest),
all_pairs_safe(Rest).
% ---- Generate a placement -------------------------------------------
%
% Placement = [rook-(R1,C1), rook-(R2,C2),
% bishop-(R3,C3), bishop-(R4,C4),
% knight-(R5,C5), knight-(R6,C6)]
%
% We enforce an ordering within each pair to avoid counting
% same-type duplicates (rook1 vs rook2 swapped).
% Squares are represented canonically: (R,C) with R*4+C as index.
sq_index(R, C, I) :- I is R*4 + C.
placement(Placement) :-
% --- Rooks ---
square(R1r, C1r), square(R2r, C2r),
sq_index(R1r,C1r,I1r), sq_index(R2r,C2r,I2r),
I1r < I2r, % canonical order for the two rooks
% --- Bishops ---
square(R1b, C1b), square(R2b, C2b),
sq_index(R1b,C1b,I1b), sq_index(R2b,C2b,I2b),
I1b < I2b, % canonical order for the two bishops
% --- Knights ---
square(R1n, C1n), square(R2n, C2n),
sq_index(R1n,C1n,I1n), sq_index(R2n,C2n,I2n),
I1n < I2n, % canonical order for the two knights % --- All six squares distinct --- Squares = [(R1r,C1r),(R2r,C2r),(R1b,C1b),(R2b,C2b),(R1n,C1n),(R2n,C2n)], all_distinct_squares(Squares), % --- Build placement list --- Placement = [ rook-(R1r,C1r), rook-(R2r,C2r), bishop-(R1b,C1b), bishop-(R2b,C2b), knight-(R1n,C1n), knight-(R2n,C2n) ], % --- No piece attacks any other --- all_pairs_safe(Placement). all_distinct_squares([]). all_distinct_squares([S|Rest]) :- \+ member(S, Rest), all_distinct_squares(Rest). % ---- Count all solutions -------------------------------------------- count_solutions(N) :- findall(P, placement(P), Ps), length(Ps, N), format("Total solutions (raw): ~w~n", [N]). % ---- D4 symmetry transformations on a 4x4 board --------------------- % Squares (R,C) in 0..3 transform(identity, R, C, R, C). transform(rot90, R, C, C, Nr) :- Nr is 3-R. transform(rot180, R, C, Nr, Nc) :- Nr is 3-R, Nc is 3-C. transform(rot270, R, C, Nc, R) :- Nc is 3-C. transform(flipH, R, C, R, Nc) :- Nc is 3-C. transform(flipV, R, C, Nr, C) :- Nr is 3-R. transform(flipD1, R, C, C, R). transform(flipD2, R, C, Nr, Nc) :- Nr is 3-C, Nc is 3-R. apply_transform(_, [], []). apply_transform(T, [Type-(R,C)|Rest], [Type-(NR,NC)|TRest]) :- transform(T, R, C, NR, NC), apply_transform(T, Rest, TRest). % Canonical form: sort pieces within same-type pairs, then sort the % whole list to get a unique representative. canonical_placement(Placement, Canonical) :- findall(T, member(T,[identity,rot90,rot180,rot270, flipH,flipV,flipD1,flipD2]), Ts), maplist(transform_and_sort(Placement), Ts, AllForms), msort(AllForms, Sorted), Sorted = [Canonical|_]. transform_and_sort(Placement, T, Sorted) :- apply_transform(T, Placement, TPl), msort(TPl, Sorted). % ---- Count solutions up to D4 symmetry ------------------------------ count_unique(N) :- findall(P, placement(P), Ps), maplist(canonical_placement, Ps, Canonicals), list_to_set(Canonicals, Unique), length(Unique, N), format("Solutions up to D4 symmetry: ~w~n", [N]). % ---- Pretty-print a board ------------------------------------------- print_board(Placement) :- forall(member(R, [0,1,2,3]), print_row(R, Placement)), nl. print_row(R, Placement) :- forall(member(C, [0,1,2,3]), print_cell(R, C, Placement)), nl. print_cell(R, C, Placement) :- ( member(rook-(R,C), Placement) -> write('R ')
; member(bishop-(R,C), Placement) -> write('B ')
; member(knight-(R,C), Placement) -> write('N ')
; write('. ')
).
% ---- Print all unique solutions -------------------------------------
print_unique_solutions :-
findall(P, placement(P), Ps),
maplist(canonical_placement, Ps, Canonicals),
list_to_set(Canonicals, Unique),
length(Unique, N),
format("~nSolutions up to D4 symmetry: ~w~n~n", [N]),
forall(nth1(I, Unique, Sol),
( format("Solution ~w:~n", [I]),
print_board(Sol) )).
% ---- Top-level entry point ------------------------------------------
run :-
count_solutions(Raw),
count_unique(Sym),
format("~n"),
print_unique_solutions,
format("Summary: ~w raw solutions, ~w up to D4 symmetry.~n",
[Raw, Sym]).