Erik Meijer’s paper Your Mouse is a Database has an interesting illustration of “The Big Data Cube” using three axes to classify databases.
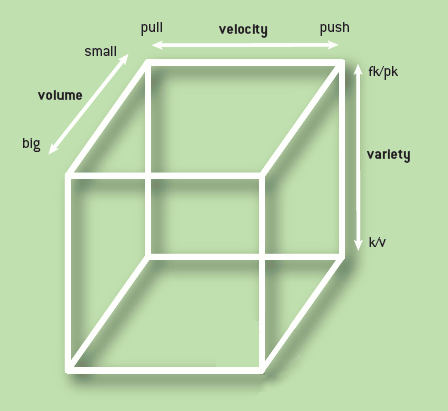
The volume axis is big vs. small, or perhaps better, open vs. closed. Relational databases can be large, and non-relational databases can be small. But the relational database model is closed in the sense that “it assumes a closed world that is under full control by the database.”
The velocity axis is (synchronous) pull vs. (asynchronous) push. The variety axis captures whether data is stored by foreign-key/primary-key relations or key-value pairs.
Here are the corners identified by the paper:
- Traditional RDBMS (small, pull, fk/pk)
- Hadoop HBase (big, pull, fk/pk)
- Object/relational mappers (small, pull, k/v)
- LINQ to Objects (big, pull, k/v)
- Reactive Extensions (big, push, k/v)
How would you fill in the three corners not listed above?
Related links:
- Big data is not enough
- Big data and humility
- coSQL (exploring the variety axis)
The bigness of “big data” is its least salient feature. It is also fast, flat, and fuzzy, but even these characteristics are merely annoying.
The single most important thing to understand about big data is that its signal-to-noise ratio is much lower than you think it is — and you probably already thought it was pretty %^$#ing low.
REST is probably best described as big, push, k/v (same as Reactive Environments).
But what about DNS? Should it’s volume be classified as closed, because of its strict delegation, or open because of its distributed nature and multiple points of administration? Should it’s variety be classified as fk/pk because queries can return collections, or should we think of those collections as values? Should its velocity be classified as push because of how the DNS protocol works or pull because of zone transfers?