The latest episode of Star Trek Discovery (S1E4) uses the word “supercomputer” a few times. This sounds jarring. The word has become less common in contemporary usage, and seems even more out of place in a work of fiction set more than two centuries in the future.
According to Google’s Ngram Viewer, the term “supercomputer” peaked in 1990.
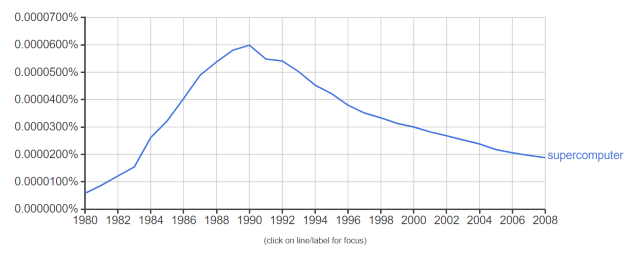
(The term “cluster” is far more common, but it is mostly a non-technical term. It’s used in connection with grapes, for example, much more often than with computers.)
Years ago you’d hear someone say a problem would take a “big computer,” but these days you’re more likely to hear someone say a problem is going to take “a lot of computing power.” Hearing that a problem is going to require a “big computer” sounds as dated as saying something would take “a big generator” rather than saying it would take a lot of electricity.
Like electricity, computing power has been commoditized. We tend to think in terms of the total amount of computing resources needed, measured in, say, CPU-hours or number of low-level operations. We don’t think first about what configuration of machines would deliver these resources any more than we’d first think about what machines it would take to deliver a certain quantity of electrical power.
There are still supercomputers and problems that require them, though an increasing number of computationally intense projects do not require such specialized hardware.
Some of my friends at Livermore ran half a trillion transactions per second on 2 million cores on the Sequoia “supercomputer.” I would love to see this kind of thing in the cloud someday soon.
https://www.hpcwire.com/2013/05/06/sequoia_hits_warp_speed/