Here’s an amusing little Python program to convert integers to Roman numerals:
def roman(n): print(chr(0x215F + n))
It only works if n is between 1 and 12. That’s because Unicode contains characters for the Roman numerals I through XII.
Here are the characters it produces:
Ⅰ Ⅱ Ⅲ Ⅳ Ⅴ Ⅵ Ⅶ Ⅷ Ⅸ Ⅹ Ⅺ Ⅻ
You may not be able to see these, depending on what fonts you have installed. I can see them in my browser, but when I ran the code above in a terminal window I only saw a missing glyph placeholder.
If you can be sure your reader can see the characters, say in print rather than on the web, the single-character Roman numerals look nice, and they make it clear that they’re to be interpreted as Roman numerals.
Here’s a screenshot of the symbols.
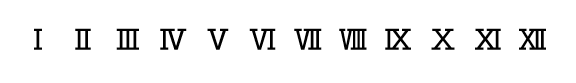
That’s pretty interesting! I guess those combinations are common enough that they decided to include them in the character set instead of requiring composition. I can see the characters fine in my terminal using the Powerline font set.
https://github.com/powerline/fonts
Since you haven’t put a guard in for numbers over 12, what chapter title would you get for chapter 13 when you add a chapter late at night and resend the pdf to the printers…?
You would get Roman-numeraled chapter 50, then 100, 500, and 1000, and then start back at 1 but in lowercase.
https://www.unicode.org/charts/PDF/U2150.pdf
The reason they have this encoding is for East Asian typesetting, specifically in vertical text. They explicitly take up exactly one cell and do not rotate as the ordinary letters would.