On Monday I wrote a blog post that showed you can estimate the standard deviation of a set of data by first computing its range and then multiplying by a constant. The advantage is that it’s easy to compute a range, but computing a standard deviation in your head would be tedious to say the least.
The problem, or the interesting part, depending on your perspective, is the constants dn you have to multiply the range by.
Yesterday before work I wrote a blog post about a proposed approximation dn and yesterday after work I wrote a post on the exact values.
There have been a couple suggestions in the comments for how to approximate dn, namely √n and log n. There’s merit to both over different ranges.
Here’s a plot of dn and √n. You can see that √n is an excellent approximation to dn for n between 3 and 10: the gold and blue dots overlap. But for larger n, √n grows too fast. It keeps going while dn sorta plateaus.
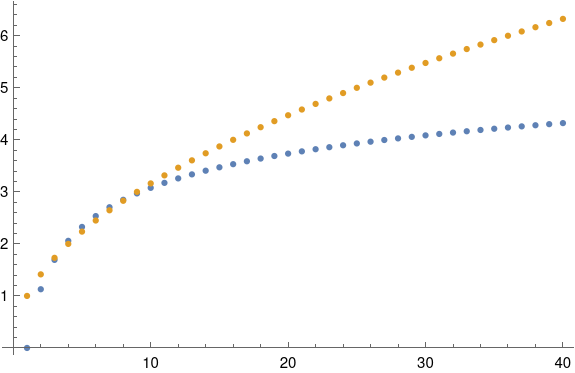
For larger n, see this post.
Please add labels to your plots with more than one line.
> But for larger n, √n grows too fast. It keeps going while √n sorta plateaus.
The second √n should be, I think, d_n instead.