When a function is not differentiable in the classical sense there are multiple ways to compute a generalized derivative. This post will look at three generalizations of the classical derivative, each applied to the ReLU (rectified linear unit) function. The ReLU function is a commonly used activation function for neural networks. It’s also called the ramp function for obvious reasons.
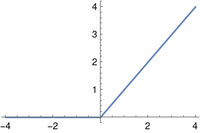
The function is simply r(x) = max(0, x).
Pointwise derivative
The pointwise derivative would be 0 for x < 0, 1 for x > 0, and undefined at x = 0. So except at 0, the pointwise derivative of the ramp function is the Heaviside function.
![]()
In a real analysis course, you’d simply say r′(x) =H(x) because functions are only defined up to equivalent modulo sets of measure zero, i.e. the definition at x = 0 doesn’t matter.
Distributional derivative
In distribution theory you’d identify the function r(x) with the distribution whose action on a test function φ is
![]()
Then the derivative of r would be the distribution r′ satisfying
![]()
for all smooth functions φ with compact support. You can prove using integration by parts that the above equals the integral of φ from 0 to ∞, which is the same as the action of H(x) on φ.
In this case the distributional derivative of r is the same as the pointwise derivative of r interpreted as a distribution. This does not happen in general. For example, the pointwise derivative of H is zero but the distributional derivative of H is δ, the Dirac delta distribution.
For more on distributional derivatives, see How to differentiate a non-differentiable function.
Subgradient
The subgradient of a function f at a point x, written ∂f(x), is the set of slopes of tangent lines to the graph of f at x. If f is differentiable at x, then there is only one slope, namely f′(x), and we typically say the subtradient of f at x is simply f′(x) when strictly speaking we should say it is the one-element set {f′(x)}.
A line tangent to the graph of the ReLU function at a negative value of x has slope 0, and a tangent line at a positive x has slope 1. But because there’s a sharp corner at x = 0, a tangent at this point could have any slope between 0 and 1.
![\partial f(x) = \left\{ \begin{array}{cl} 1 & \text{if } x > 0 \\<br /> \left[0,1\right] & \text{if } x = 0 \\<br /> 0 & \text{if } x < 0 \end{array} \right.](https://www.johndcook.com/subgradient.svg)
My dissertation was full of subgradients of convex functions. This made me uneasy because subgradients are not real-valued functions; they’re set-valued functions. Most of the time you can blithely ignore this distinction, but there’s always a nagging suspicion that it’s going to bite you unexpectedly.