In an earlier post, I compared three methods of computing sample variance. All would give the same result in exact arithmetic, but on a computer they can give very different results. Here I will explain why the results were so bad using the sum of squares formula

but were much better using the direct formula
![]()
(The third method, Welford’s method, is preferable to both of the above methods, but its accuracy is more similar to the direct formula.)
In the numerical examples from the previous post, I computed the sample variance of xi = N + ui where N was a large number (106, 109, or 1012) and the ui were one million (106) samples drawn uniformly from the unit interval (0, 1). In exact arithmetic, adding N to a sample does not change its variance, but in floating point arithmetic it matters a great deal.
When N equaled 109, the direct formula correctly reported 0.083226511 while the sum of squares method gave −37154.734 even though variance cannot be negative. Why was one method so good and the other so bad? Before we can answer that, we have to recall the cardinal rule of numerical computing:
If x and y agree to m significant figures, up to m significant figures can be lost in computing x − y.
We’ll use the rule as stated above, though it’s not exactly correct. Since arithmetic is carried out in binary, the rule more accurately says
If x and y agree to m bits, up to m bits of precision can be lost in computing x − y.
Now back to our problem. When we use the direct formula, we subtract the mean from each sample. The mean will be around N + 1/2 and each sample will be between N and N + 1. So a typical sample agrees with the mean to around 9 significant figures since N = 109. A double precision floating point number contains about 15 significant figures, so we retain about 6 figures in each calculation. We’d expect our final result to be accurate to around 6 figures.
Now let’s look at the sum of squares formula. With this approach, we are computing the sample variance as the difference of
![]()
and
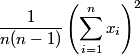
These two expressions are both on the order of N2, or 1018. The true sample variance is on the order of 10−1, so we’re subtracting two numbers that if calculated exactly would agree to around 19 significant figures. But we only have 15 significant figures in a double and so it should not be surprising that our answer is rubbish.
Now let’s go back and look at the case where N = 106. When we use the direct method, we expect to lose 6 significant figures in subtracting off the mean, and so we would retain 9 significant figures. When we use the sum of squares formula, the two sums that we subtract are on the order of 1012 and so we’re trying to calculate a number on the order of 10−1 as the difference of two numbers on the order of 1012. We would expect in this case to lose 13 significant figures in the subtraction. Since we start with 15, that means we’d expect about 2 significant figures in our answer. And that’s exactly what happened.
Update: See related posts on simple regression coefficients and Pearson’s correlation coefficient.
While working on my undergraduate thesis, I had to choose a convenient way to calculate variance using a DSP (for finding the power of two signals). That’s how I came across your blog and I decided to implement my design using the methods of: direct formula method and Welford’s method having satisfactory results with both of them, but overall preferring the Welford’s method.
In the book of my thesis I mentioned the disadvantages that you pointed out about the sum of squares formula, but now I’m being asked for a more formal bibliographical source (I put a link to this blog entry) or for an statistical study. I appreciate if you could tell me how to find any of those sources because if I can’t give those references I’ll have to remove the whole topic of the selection of the variance method, and I wouldn’t like that because I think it was very relevant in the design.
Thank you so much for your help
Diana: Please see the references at the bottom of this page.
Thank you again! I don’t why I didn’t see it before :O
“I don’t know”
The link to the previous article in the sequel at the top of the post is broken, it should be http://www.johndcook.com/blog/2008/09/26/comparing-three-methods-of-computing-standard-deviation/
Great post!
Marios: Thanks. I updated the link.
John: I’m curious as to the accuracy of Welford’s method (at least the part for computing the mean) compared to sorting a list of numbers into increasing order, then summing the numbers in increasing order, and then dividing by N to get the mean. (This is the standard rule of thumb for avoiding loss of precision when the orders of magnitude of the numbers vary.)
It looks to me that Welford’s method will suffer greatly from loss of precision issues under random reorderings of values spanning several orders of magnitude, because the sum (x_k – M_{k-1}) will lose bits when M_{k-1} is much larger than x_k?
Dear John,
Welford’s method is great to calculate the standard deviation “online”, i.e. if data comes in one after another. Earlier this year, I programmed a calculation of mean and standard deviation that was stabilised as follows: Find an estimate of the mean (e. g. the first sample). Shift the data by this estimated mean, calculate mean and standard deviation of the shifted data using the sum-of-squares method, then shift the mean back. It is even simpler than the direct method, as it requires only one pass through the data. Also, I found it easier to understand than Welford’s formulas – important if you want to convince someone that your code is correct.
This algorithm is recommended on the wikipedia pageAlgorithms for calculating variance, which refers to T.F. Chan, G.H. Golub and R.J. LeVeque: Algorithms for computing the sample variance: Analysis and recommendations. The American Statistician, 37(3)1983. pp. 242–247. (See in particular Section 3 of that article.)
Finally, please note that you calculate the sample standard deviation. While this is what in most statistics is needed, the difference to (population) standard deviation should be made clear.
Well, to followup on my previous comment: I see that you already refer to exactly these sources on other pages, so you are aware of them. Then I am curious what you would consider as advantages of Welford over the stabilisation that I proposed.
The sum of squares is a perfectly valid solution. The problem is the math library you selected. If you use a library with quad doubles or higher precision, the results will be meaningful.
Experience is a hard teacher. The test comes first and the lessons come later.