Suppose you have a set of points and you want to fit a straight line to the data. I’ll present two ways of doing this, one that works better numerically than the other.
Given points (x1, y1), …, (xN, yN) we want to fit the best line of the form y = mx + b, best in the sense of minimizing the square of the differences between the actual data yi values and the predicted values mxi + b.
The textbook solution is the following sequence of equations.
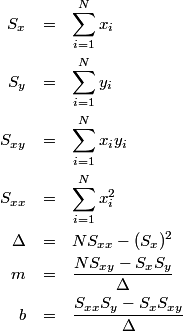
The equations above are absolutely correct, but turning them directly into software isn’t the best approach. Given vectors of x and y values, here is C++ code to compute the slope m and the intercept b directly from the equations above.
double sx = 0.0, sy = 0.0, sxx = 0.0, sxy = 0.0;
int n = x.size();
for (int i = 0; i < n; ++i)
{
sx += x[i];
sy += y[i];
sxx += x[i]*x[i];
sxy += x[i]*y[i];
}
double delta = n*sxx - sx*sx;
double slope = (n*sxy - sx*sy)/delta;
double intercept = (sxx*sy - sx*sxy)/delta;
This direct method often works. However, it presents multiple opportunities for loss of precision. First of all, the Δ term is the same calculation criticized in this post on computing standard deviation. If the x values are large relative to their variance, the Δ term can be inaccurate, possibly wildly inaccurate.
The problem with computing Δ directly is that it could potentially require subtracting nearly equal numbers. You always want to avoid computing a small number as the difference of two big numbers if you can. The equations for slope and intercept have a similar vulnerability.
The second method is algebraically equivalent to the method above, but it is better suited to numerical calculation. Here it is in code.
double sx = 0.0, sy = 0.0, stt = 0.0, sts = 0.0;
int n = x.size();
for (int i = 0; i < n; ++i)
{
sx += x[i];
sy += y[i];
}
for (int i = 0; i < n; ++i)
{
double t = x[i] - sx/n;
stt += t*t;
sts += t*y[i];
}
double slope = sts/stt;
double intercept = (sy - sx*slope)/n;
This method involves subtraction, and it too can fail for some data sets. But in general it does better than the former method.
Here are a couple examples to show how the latter method can succeed when the former method fails.
First we populate x and y as follows.
for (int i = 0; i < numSamples; ++i)
{
x[i] = 1e10 + i;
y[i] = 3*x[i] + 1e10 + 100*GetNormal();
}
Here GetNormal() is generator for standard normal random variables. Aside from some small change due to the random noise, we would expect slope 3 and intercept 1010.
The most direct method gives slope −0.666667 and intercept 5.15396e+10. The better method gives slope: 3.01055 and intercept: 9.8945e+9. If we remove the Gaussian noise and try again, the direct method gives slope 3.33333 and intercept 5.72662e+9 while the better method is exactly correct: slope 3 intercept and 1e+10.
As another example, fill x and y as follows.
for (int i = 0; i < numSamples; ++i)
{
x[i] = 1e6*i;
y[i] = 1e6*x[i] + 50 + GetNormal();
}
Now both method compute the intercept exactly as 1e6 but the direct method computes the intercept as 60.0686 while the second method computes 52.416. Neither is very close to the theoretical value of 50, but the latter method is closer.
To read more about why one way can be so much better than the other, see this writeup on the analogous issue with computing standard deviation: theoretical explanation for numerical results.
Update: See related post on computing correlation coefficients.
Hi,
Thanks for the post, I found it very informative. I stumbled upon your blog when I was looking for alternate ways to a fit a straight line to a set of data points. I currently employ the method of calculating the least squares approximation of the line using linear algebra techniques; I found that my current technique worked for one of my data sets but the methods you posted here did not. I was wondering if you could explain to me why it didn’t work, or if you could please possibly direct me to some other source of information so that I can understand why it doesn’t work. The data set which I mentioned is below:
X_Values = {0.653392, 0.655975, 0.649529, 0.642886, 0.644527, 0.645786, 0.638369, 0.638948, 0.647223, 0.646904, 0.638298, 0.645040, 0.643486, 0.641512, 0.639113, 0.636286, 0.640221, 0.643475, 0.639094, 0.634266, 0.635682, 0.629824, 0.629939, 0.629328, 0.627982, 0.631913, 0.634815, 0.625205, 0.626303, 0.626341, 0.620012, 0.618052, 0.620006, 0.620562, 0.610319, 0.608353, 0.600574};
Y_Values = {0.347414, 0.363613, 0.375006, 0.386285, 0.402745, 0.419378, 0.430585, 0.447396, 0.470235, 0.487477, 0.498693, 0.522343, 0.539949, 0.557658, 0.575460, 0.593347, 0.618254, 0.643475, 0.661801, 0.680168, 0.705996, 0.724530, 0.750733, 0.777155, 0.803780, 0.838577, 0.873748, 0.892885, 0.928532, 0.964481, 0.992226, 1.028611, 1.073882, 1.119524, 1.147842, 1.193959, 1.231358};
The line is almost vertical; and I have a feeling that this is why the method here on your post fails. With my current method I get a gradient of -19.569292 and an intercept of 13.112316; I know that these values are correct for the data set because I plotted the values on Excel and added a trend line, the trend line had the same parameters as the ones I have mentioned above. Thanks in advance for you help.
Kind Regards,
Tony