From Zero to One:
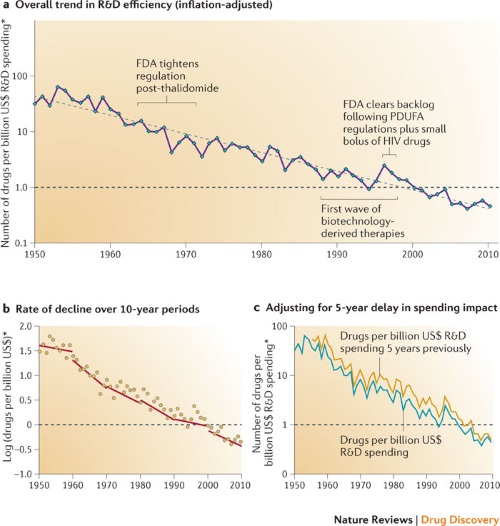
Eroom’s law — that’s Moore’s law backward — observes that the number of new drugs approved per billion dollars spent on R&D has halved every nine years since 1950.
Update: Here’s an article from Nature that gives more details. The trend is pretty flat on a log scale, i.e. exponentially declining efficiency.
Related: Adaptive clinical trial design
I feel super-awed whenever I visit a pharmacy because I think of all the investment that went in, by the pharma companies, the researchers working on those drugs, the human trials, the approvals, etc, to make that one tablet, that targets that one organ, and cures exactly whatever is causing the disease. It’s truly remarkable.
It does take a tremendous amount of effort and investment, but you have to wonder why drug discovery is becoming exponentially less efficient, even as computers are becoming exponentially more efficient. You’d think that drug discovery might benefit indirectly from Moore’s law, as other industries have.
The metric here is simply the number of drugs. What would things look like if the numbers were weighted by their medical impact? The picture might be more bleak. A lot of drugs require enormous clinical trials because the improvement they provide is small.
That flattening is normal for a given technology. It’s the S-curve. Even Moore’s law looks like that. Moore’s law described the data at that time. S-curves were already known at the time.
The question is where will we find the next discontinuity that will jump from this curve to a steeper one headed in the other direction. How many underlying technologies support finding a cure? What will the next one be? How many cures will be based on it. If everyone is looking or a cure, then nobody is looking for the next underlying technology.
The convergence demonstrated in this cure hints at the need for a radical shift in cure seeking infrastructure.
I don’t think the comparison is entirely fair. As you noted, it’s assessing number of drugs, not impact or effectiveness. Also, it’s basing it on investment – Moore’s second law notes that the cost of generating new chips increases exponentially.
DNA sequencing has benefited from Moore’s law. Maybe we’re at the point where this will yield an increase in efficiency in the development of new drugs.
I assume we are making new treatments faster than nature is making new ailments. Low hanging fruit is disappearing. Is this some form of survivor bias?
I imagine that there was an exponential period in pharmaceutical discovery, and we are simply past that point. Conceivably the same thing will happen to computers.
In fact, I suspect it already has, provided you have a more refined measure that Gflops. It takes me way longer to code up a CUDA app than a C++11 threaded app, and way longer to code a C++11 threaded app than a serial app.
I’ll bet the total cost of delivering a stable HPC app is increasing exponentially-provided you count developer time, beta testing, sitting around wondering if the results are right . . .
at least one reason is nothing to do with drug discovery but to do with getting approval.
The number of patients enrolled in studies used for submission is going up. My guess is it is 100 times what it was 20 years ago. This has a direct effect on costs. It would not surprise me if the average fees to doctors per enrolled patient was also going up.
You could argue I suppose that safety is a concern because the new drugs are follow on substances rather than totally new.
I would still like to see the numbers. :-)
Another thought occurs, I will read the paper to see, but what if the measure is drugs getting approved?
The it could just be an artifact introduced because the number of candidates being progressed through stage 3 trials is higher, but more are withdrawn within the companies before approval. So the cost per approval is soaring.