How much information is conveyed by a single Chinese character? This post addresses that question by computing Shannon entropy.
First of all, information theory defines the Shannon entropy of an “alphabet” to be

bits where pi is the probability of the ith “letter” occurring and the sum is over all letters. I put alphabet and letter in quotes because information theory uses these terms for any collection of symbols. The collection could be a literal alphabet, like the Roman alphabet, or it could be something very different, such as a set of musical notes. For this post it will be a set of Chinese characters.
I’ll use a set of data on Chinese character frequency by Jun Da. See that site for details.
Here’s a plot of the character frequencies on a logarithmic scale.
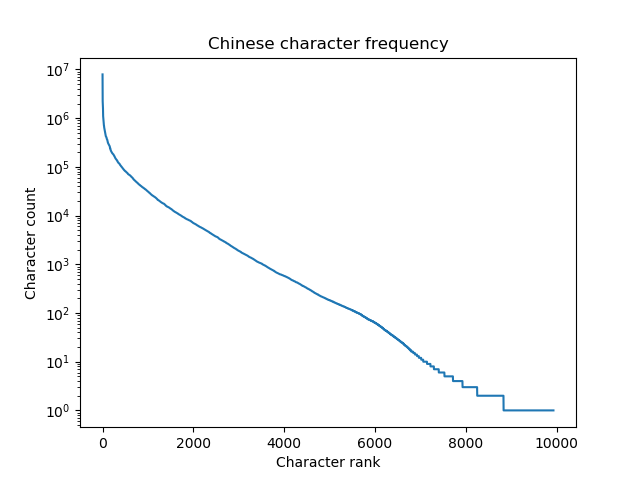
Jun Da’s data set contains 9,933 characters. The most common character, 的, appears 7,922,684 times in the language corpus and the least common character on the list, 鴒, appears once. The 1,000 most common characters account for 89% of use.
The Shannon entropy of the Chinese “alphabet” is 9.56 bits per character. By comparison, the entropy of the English alphabet is 3.9 bits per letter.
The entropy of individual symbols doesn’t tell the whole story of the information density of the two writing systems. Symbols are not independent, and so the information content of a sequence of symbols will be less than just multiplying the information content per symbol by the number of symbols. I imagine there is more sequential correlation between consecutive English letters than between consecutive Chinese characters, though I haven’t seen any data on that. If this is the case, just looking at the entropy of single characters underestimates the relative information density of Chinese writing.
Although writing vary substantially in how much information they convey per symbol, spoken languages may all convey about the same amount of information per unit of time.
A few weeks ago I wrote about new research suggesting that all human languages convey information at about the same rate. Some languages carry more information per syllable than others, as measured by Shannon entropy, but these languages are typically spoken more slowly. The net result is that people convey about 40 bits of information per second, independent of their language. Of course there are variations by region, by individual, etc. And there are limits to any study, though the study in question did consider a wide variety of languages.
Thanks! Wow. That was fast.
FWIW, in both Chinese and Japanese many words consist of two Chinese characters. Japanese is messier because it’s actually two languages combined: the underlying Japanese language plus an incredibly large number of words borrowed from Chinese. But since these words consist of specific characters, there will be strong correlations. (Irrelevant aside: both Chinese and Japanese do not use whitespace to indicate word breaks, so to do anything computational linguistically with the languages, you have to actually parse each sentence.) From ancient memory (I took one term of Chinese many many years ago), verbs and prepositions and the like in Chinese are often one character. In Japanese, the words in the underlying language are usually written with one character (plus some Japanese phonetics). So there are two statistically different classes of Chinese character usage going on.
Great article! I didn’t expect a follow up on your previous one so quickly.
I found this topic very intriguing, so I tried to calculate the entropy using bigrams[2] (by using an order-1 Markov model for the text).
Fortunately, Da’s page has Bigram frequency lists as well, so I used the news corpus from that page. When using the informative Modern Chinese corpus for the marginal probabilities, I got a 0th order entropy of 9.56 bits and 1st order entropy of 4.04 bits (by the way, I think your 6.7 figure is given in units of nats instead of bits). When using the entire Modern Chinese corpus (literature + informative), I have the same Shannon entropy as you, 9.66 bits and a 2nd letter entropy of 4.24 bits. That’s quite a large difference!
For reference, in Shannon’s original paper on entropy in entropy in English, he calculates zeroth and first order entropy rates of 4.70 and 4.14 [1].
[1] Page discussing Shannon’s original calculation of entropy in English, although he also used some more clever tricks to get other measures as well. https://people.seas.harvard.edu/~jones/cscie129/papers/stanford_info_paper/entropy_of_english_9.htm
[2] code I used – https://gist.github.com/bluecookies/c78fe32954c1db44989e34abe2efa405. Note: data downloaded from Da’s page is encoded in GB.
Would it possible to compute the Shannon entropy of formulas and equations in math papers? I guess ‘+’ and ‘=’ would be the top 2 characters and entropy should be higher than all natural languages.
I saw something along those lines recently, comparing source code with math:
http://shape-of-code.coding-guidelines.com/2019/10/13/comparing-expression-usage-in-mathematics-and-c-source/
For example, + is more common in source code, and – is more common in math. I suppose it’s because programs are constructive, build up results from pieces, whereas math is often comparing things by looking at their difference.
Thank you for this interesting topic!
I tried the same for Hebrew, taken over Pentateuch and “newspaper” frequencies (source: http://www.tapuz.co.il/blogs/viewentry/1638662).
We get 4.057 for Pentateuch Hebrew and 3.717 for “modern” newspaper Hebrew.
I did some other calculations about Chinese which are about the ‘pinyin’ system. I know there are 5000+ Chinese characters, but there are much less when they pronounce. if considering tones, there are about 1200 combinations. The top 5 are (the numbers are occurrence count in Jun Da’s data):
de 8967761
shi4 4309209
yi1 3308787
bu4 2889212
ta1 2334584
If not considering tones, there are about 300 combinations. The top 5 are:
de 9767428
shi 6965175
yi 5885089
ji 3063392
bu 2945133
The entropy values to the above two cases are 6.75 and 5.75, which are much lower than written characters. This can explain a lot of things:
Many ones think Chinese people talk loudly.
Chinese like to watch videos with subtitles even if they are in the Chinese language.
Chinese people don’t like voice messages.
etc..
I think this can be a researching area for someone.
Typing standards states that an English Word (defined as one of: root word, prefix, suffix; not a compound word) is five letters and a space, so the Shannon Entropy of an English Word should be 5×3.9=19.5 for an equivalent unit of meaning.