Heaps’ law says that the number of unique words in a text of n words is approximated by
V(n) = K nβ
where K is a positive constant and β is between 0 and 1. According to the Wikipedia article on Heaps’ law, K is often between 10 and 100 and β is often between 0.4 and 0.6.
(Note that it’s Heaps’ law, not Heap’s law. The law is named after Harold Stanley Heaps. However, true to Stigler’s law of eponymy, the law was first observed by someone else, Gustav Herdan.)
I’ll demonstrate Heaps’ law looking at books of the Bible and then by looking at novels of Jane Austen. I’ll also look at unique words, what linguists call “hapax legomena.”
Demonstrating Heaps’ law
For a collection of related texts, you can estimate the parameters K and β from data. I decided to see how well Heaps’ law worked in predicting the number of unique words in each book of the Bible. I used the King James Version because it is easy to download from Project Gutenberg.
I converted each line to lower case, replaced all non-alphabetic characters with spaces, and split the text on spaces to obtain a list of words. This gave the following statistics:
|------------+-------+------|
| Book | n | V |
|------------+-------+------|
| Genesis | 38520 | 2448 |
| Exodus | 32767 | 2024 |
| Leviticus | 24621 | 1412 |
...
| III John | 295 | 155 |
| Jude | 609 | 295 |
| Revelation | 12003 | 1283 |
|------------+-------+------|
The parameter values that best fit the data were K = 10.64 and β = 0.518, in keeping with the typical ranges of these parameters.
Here’s a sample of how the actual vocabulary size and modeled vocabulary size compare.
|------------+------+-------|
| Book | True | Model |
|------------+------+-------|
| Genesis | 2448 | 2538 |
| Exodus | 2024 | 2335 |
| Leviticus | 1412 | 2013 |
...
| III John | 155 | 203 |
| Jude | 295 | 296 |
| Revelation | 1283 | 1387 |
|------------+------+-------|
Here’s a visual representation of the results.
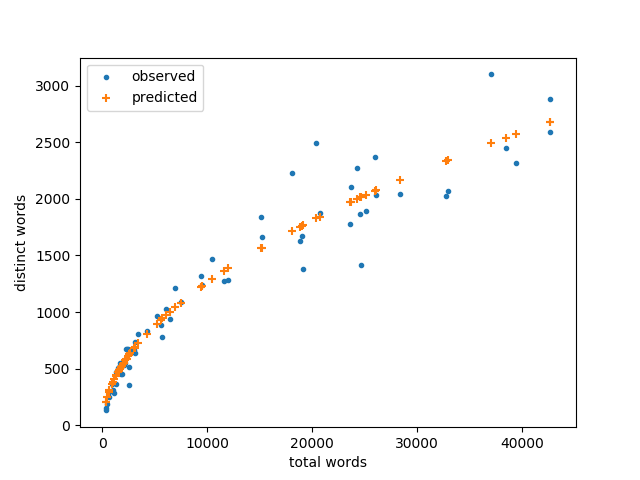
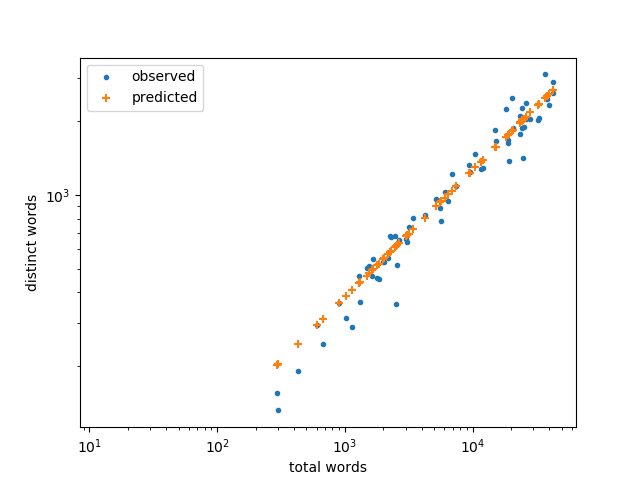
It looks like the model is more accurate for small books, and that’s true on an absolute scale. But the relative error is actually smaller for large books as we can see by plotting again on a log-log scale.
Jane Austen novels
It’s a little surprising that Heaps’ law applies well to books of the Bible since the books were composed over centuries and in two different languages. On the other hand, the same committee translated all the books into English at the same time. Maybe Heaps’ law applies to translations better than it applies to the original texts.
I expect Heaps’ law would fit more closely if you looked at, say, all the novels by a particular author, especially if the author wrote all the books in his or her prime. (I believe I read that someone did a vocabulary analysis of Agatha Christie’s novels and detected a decrease in her vocabulary in her latter years.)
To test this out I looked at Jane Austen’s novels on Project Gutenberg. Here’s the data:
|-----------------------+--------+------|
| Novel | n | V |
|-----------------------+--------+------|
| Northanger Abbey | 78147 | 5995 |
| Persuasion | 84117 | 5738 |
| Sense and Sensibility | 120716 | 6271 |
| Pride and Prejudice | 122811 | 6258 |
| Mansfield Park | 161454 | 7758 |
| Emma | 161967 | 7092 |
|-----------------------+--------+------|
The parameters in Heaps’ law work out to K = 121.3 and β = 0.341, a much larger K than before, and a smaller β.
Here’s a comparison of the actual and predicted vocabulary sizes in the novels.
|-----------------------+------+-------|
| Novel | True | Model |
|-----------------------+------+-------|
| Northanger Abbey | 5995 | 5656 |
| Persuasion | 5738 | 5799 |
| Sense and Sensibility | 6271 | 6560 |
| Pride and Prejudice | 6258 | 6598 |
| Mansfield Park | 7758 | 7243 |
| Emma | 7092 | 7251 |
|-----------------------+------+-------|
If a suspected posthumous manuscript of Jane Austen were to appear, a possible test of authenticity would be to look at its vocabulary size to see if it is consistent with her other works. One could also look at the number of words used only once, as we discuss next.
Hapax legomena
In linguistics, a hapax legomenon is a word that only appears once in a given context. The term comes from a Greek phrase meaning something said only once. The term is often shortened to just hapax.
I thought it would be interesting to look at the number of hapax legomena in each book since I could do it with a minor tweak of the code I wrote for the first part of this post.
Normally if someone were speaking of hapax legomena in the context of the Bible, they’d be looking at unique words in the original languages, i.e. Hebrew and Greek, not in English translation. But I’m going with what I have at hand.
Here’s a plot of the number of hapax in each book of the KJV compared to the number of words in the book.
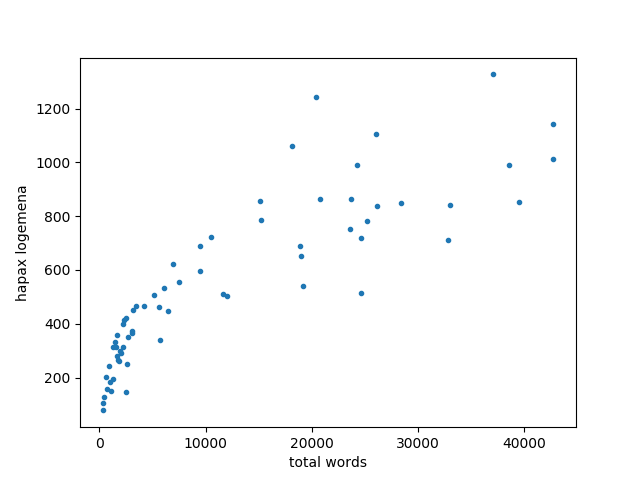
This looks a lot like the plot of vocabulary size and total words, suggesting the number of hapax also follow a power law like Heaps law. This is evident when we plot again on a logarithmic scale and see a linear relation.
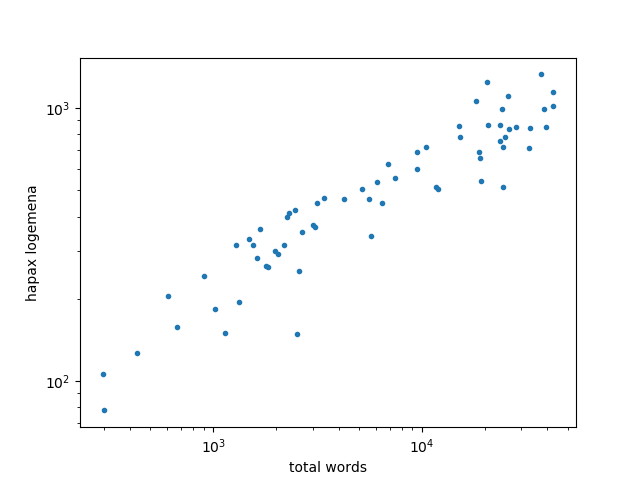
Just to be clear on the difference between two analyses this post, in the first we looked at vocabulary size, the number of distinct words in each book. In the second we looked at words that only appear once. In both cases we’re counting unique words, but unique in different senses. In the first analysis, unique means that each word only counts once, no matter how many times it’s used. In the second, unique means that a work only appears once.
Hi John,
Is there anything interesting to learn by splitting the Bible analysis up by book author?
Mike
I suppose it could help with questions of authorship. For example, does the vocabulary of Hebrews match what one would expect from Paul? But you could do a lot better than just counting words. You could look at which words the text contains.
Maybe a better use would be looking at unique words per author. A word may not be unique in the Bible as a whole, but if it is unique for a given author, we should be cautious about assuming we know how that author used the word.
I’m curious — what kind of error between predicted and actual would we expect to see if Heaps’ law weren’t true?
I’m uncertain about how this question could be answered. Perhaps by analyzing another data set with analogous concepts to “total words” and “distinct words”, but which is not text? Or can it be answered theoretically?
if Heaps’ law holds, then you can take logs and do linear regression and analyze error that way. The errors could still be large, but they would be independent, according to the usual regression assumptions. There would not be a trend in the errors as a function of n.
It’s interesting that the graph of hapax seems to be substantially noisier than the graph of distinct words, and is especially so for longer books. I’m wondering if there are additional unpredictable factors that specifically affect the number of hapax. (For example, I know that some books in the Bible contain long lists of names, which would greatly increase the number of hapax if those names don’t show up anywhere else. It would also increase the number of distinct words, but by a much smaller relative amount. This doesn’t explain the higher variance in longer books compared to shorter ones, though.)