This post shows how to export an Excel file to a CSV file using in2csv from the csvkit package.
You could always use Excel itself to export an Excel file to CSV but there are several reasons you might not want to. First and foremost, you might not have Excel. Another reason is that you might want to work from the command line in order to automate the process. Finally, you might not want the kind of CSV format that Excel exports.
For illustration I made a tiny Excel file. In order to show how commas are handled, populations contain commas but areas do not.
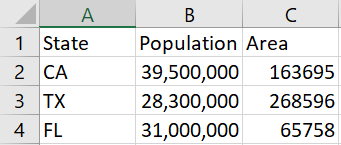
When I ask Excel to export the file I get
State,Population,Area
CA,"39,500,000",163695
TX,"28,300,000",268596
FL,"31,000,000",65758
Note that areas are exported as plain integers, but populations are exported as quoted strings containing commas.
Using csvkit
Now install csvkit and run in2csv.
$ in2csv states.xlsx
State,Population,Area
CA,39500000,163695
TX,28300000,268596
FL,31000000,65758
The output goes to standard out, though of course you could redirect the output to a file. All numbers are exported as numbers, with no thousands separators. This makes the output easier to use from a program that does crude parsing [1]. For example, suppose we save states.xlsx to states.csv using Excel then ask cut for the second column. Then we don’t get what we want.
$ cut -d, -f2 states.csv
Population
"39
"28
"31
But if we use in2csv to create states.csv then we get what we’d expect.
cut -d, -f2 states.csv
Population
39500000
28300000
31000000
Multiple sheets
So far we’ve assumed our Excel file has a single sheet. I added a second sheet with data on US territories. The sheet doesn’t have a header row just to show that the header row isn’t required.
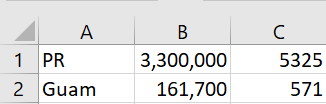
I named the two sheets “States” and “Territories” respectively.

Now if we ask in2csv to export our Excel file as before, it only exports the first sheet. But if we specify the Territories sheet, it will export that.
$ in2csv --sheet Territories states.xlsx
PR,3300000,5325
Guam,161700,571
More CSV posts
[1] The cut utility isn’t specialized for CSV files and doesn’t understand that commas inside quotation marks are not field separators. A specialized utility like csvtool would make this distinction. You could extract the second column with
csvtool col 2 states.csv
or
csvtool namedcol Population states.csv
This parses the columns correctly, but you still have to remove the quotation marks and thousands separators.