Suppose you need to compare two files with very long lines. Maybe each file is one line.
The diff utility will show you which lines differ. But if the files are each one line, this tells you almost nothing. It confirms that there is a difference, but it doesn’t show you where the difference is. It just dumps both files to the command line.
For example, I created two files each containing the opening paragraph of Moby Dick. The file file1.txt contains the paragraph verbatim, and in file2.txt contains a typo. I ran
diff temp1.txt temp2.txt
and this is what I saw:
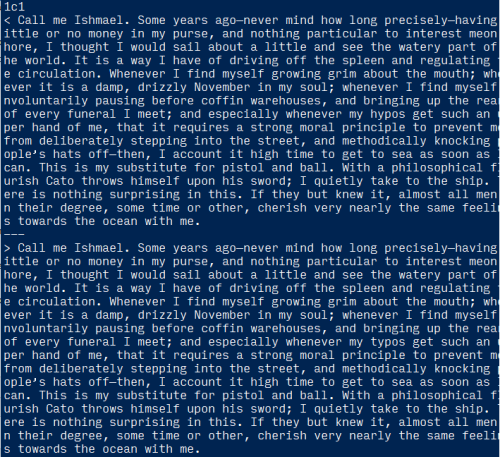
The 1c1 output tells us that the difference occurs on line 1, but that’s no help because the whole file is line 1.
There are no doubt many ways to fix this problem, but the solution I thought of was to use fold to break the files into more lines before running diff. Without any optional arguments, fold will split a file into segments of 80 characters.
Here’s my first attempt.
$ diff <(fold temp1.txt) <(fold temp2.txt)
7c7
< and bringing up the rear of every funeral I meet; and especially whenever my hy
---
> and bringing up the rear of every funeral I meet; and especially whenever my ty
That’s better, but we lost context when we chopped the file into 80-character segments. We can’t see that the last words should be “hypos” and “typos”. This is a minor inconvenience, but there’s a bigger problem.
In the example above I simply changed one character, turning an ‘h’ into a ‘t’. But suppose I had changed “hypos” into “typoes”, not only changing a letter, but also inserting a letter. Then the rest of the files would split differently into 80-character segments. Even though the rest of the text is identical, we would be seeing differences created by fold.
This problem can be mitigated by giving diff the option -s, telling it to split lines at word boundaries.
$ diff <(fold -s temp1.txt) <(fold -s temp2.txt)
8,9c8,9
< whenever my hypos get such an upper hand of me, that it requires a strong moral
< principle to prevent me from deliberately stepping into the street, and
---
> whenever my typoes get such an upper hand of me, that it requires a strong
> moral principle to prevent me from deliberately stepping into the street, and
The extra letter that I added changed the way the first line was broken; putting “moral” on the first line of the second output would have made the line 81 characters long. But other than pushing “moral” to the next line, the rest of chopped lines are the same.
You can use the -w option to have diff split lines of lengths other than 80 characters. If I split the files into lines 20 characters long, the differences between the two files are more obvious.
$ diff <(fold -s -w 20 temp1.txt) <(fold -s -w 20 temp2.txt)
34c34
< my hypos get such
---
> my typoes get such
Ah, much better.
Not only do shorter lines make it easier to see where the differences are, in this case changing the segment length fixed the problem of a word being pushed to the next line. That won’t always be the case. It would not have been the case, for example, if I had used 15-character lines. But you can always change the number of characters slightly to eliminate the problem if you’d like.
nice trick!
Similar to diffing code by statements, I wonder if the diff results would improve if lines were split by periods. That avoids segment length issues if a word’s length changes and pushes changes to the lines afterwards.
Is there a reason not to compare on a word-by-word basis, rather than messing about with choices of line lengths? I haven’t tried, but instead of fold, a command like “sed /\b/\n/g” which breaks the text at each word boundary might do the trick.
You might find wdiff helpful depending on your use cases.
https://www.gnu.org/software/wdiff/
The
-boption tocmpcan be useful.$ seq 1 100 | tr \\n ‘ ‘ > /tmp/a
$ sed ‘s/81/80/’ /tmp/b
$ cmp -b /tmp/a /tmp/b
/tmp/a /tmp/b differ: byte 233, line 1 is 61 1 60 0
$
The
61and60in the output are the octal values of the differing characters.Nice!
If you’re on a Mac, you can use the FileMerge app to see the differences between two text files. If the text files contain long lines, then you’ll want to enable Wrap Text in Preferences.
@BrianOxley – the wdiff capabilities are built in into ‘git diff’. You can use it outside of Git repository with
git diff –no-index –word-diff temp1.txt temp2.txt
Doesn’t splitting by words have the same problem if you add/remove a word?
Scott S- Diff algorithms try to find longest common subsequences of their inputs. They want to find the smallest number of edits (insertions, deletions or changes) required to match the two inputs. When you insert a word, with a word-oriented diff, it will mark that single word as needing to be inserted.
The classic diff algorithms are dynamic programming algorithms, with the two most popular credited to Hunt/Szymanski/McIlroy and to Eugene Myers. More modern optimizations try to break a large diff into smaller batches to reduce memory use or CPU time for large inputs — for example, diffing lines that occur exactly once in each input, and performing smaller diffs between corresponding unique lines. Other heuristic tweaks prefer longest common substrings (contiguous subsequences) because those edits usually make more sense for source code.
I find that using color to highlight sections of a diff is very helpful. If you’re in a CLI environment that supports it, you might consider a diff tool like https://github.com/so-fancy/diff-so-fancy.
I found this after realizing that Github’s diff highlighting was superior to whatever I was using at the command line.
I found this very useful indeed. Thanks a million