Setting up Unicode on my MacBook took some research, so I’m leaving myself a note here if I need to do it again. Maybe it’ll help someone else too.
Update: I’ve gotten some feedback on this article that suggest people imagine that I want to use this approach to enter large quantities of text, such as typing Cyrillic text one Unicode code point at a time. This is not the case. If I wanted to type Cyrillic text, I’d use a (virtual) Cyrillic keyboard. The use case I have in mind is typing symbols or maybe a single word from a foreign language.
From the System Settings dialog, go to Keyboard and click the Edit button next to Input Sources. Click on the + sign in the lower left corner to add a keyboard. Scroll down to the bottom and click on Other to add Unicode as a keyboard.
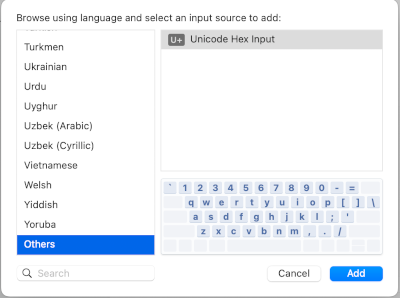
Now you can toggle between your previous keyboard(s) and Unicode Hex Input. When the latter is active, you can hold down the globe key and type the hex value of a Unicode character to enter that character. For example, you can hold down the globe key and type 03C0 to enter a π symbol.
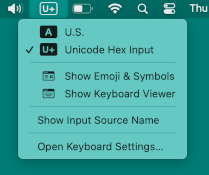
This only works for Unicode characters that can be written with four hexadecimal characters, i.e. up to FFFF, code points in the Basic Multilingual Plane.
Remapping keys
I’ve remapped my keys so that my muscle memory works across operating systems, so I have the functionality of the globe key mapped to the ⌘ key. So I hold down the key labeled “command” to enter Unicode characters. More on how I remap keys here.
Fixing Emacs
When I added the Unicode keyboard, C + space quit working in Emacs because the operating system hijacked that key. Removing the Unicode keyboard doesn’t put the system back like it was.
You can use C + @ instead of C + space for set-mark-command but this is an awkward keybinding, especially for such a common function. I bound a different key sequence to set-mark-command that I find easier to type.
Command line
See the next post for a command line script that will copy any Unicode character to the clipboard, including code points higher than the solution above can handle.
Ctrl-cmd-space brings up “Character Viewer” for me – I think that’s standard. I can search for a unicode character by code or name in that, and copy to the clipboard.