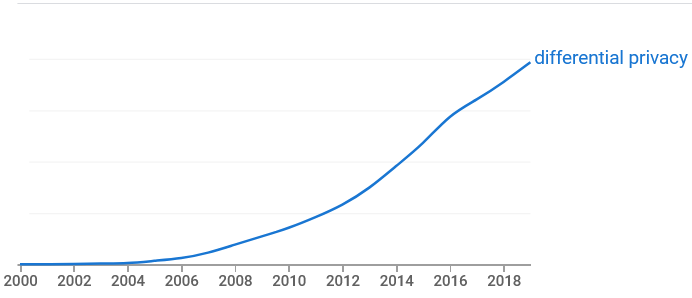
Interest in differential privacy is growing rapidly. As evidence of this, here’s the result of a Google Ngram search [1] on “differential privacy.”
When I first mentioned differential privacy to consulting leads a few years ago, not many had heard of it. Now most are familiar with the term, though they may not be clear on what it means.
The term “differential privacy” is kinda mysterious, particularly the “differential” part. Are you taking the derivative of some privacy function?!
In math and statistics, the adjective “differential” usually has something to do with calculus. Differential geometry applies calculus to geometry problems. Differential equations are equations involving the derivatives of the function you’re after.
But differential privacy is different. There is a connection to differential calculus, but it’s further up the etymological tree. Derivatives are limits of difference quotients, and that’s the connection. Differential privacy is about differences, but without any limits. In a nutshell, a system is differentially private if it hardly makes any difference whether your data is in the system or not.
The loose phrase “it hardly makes any difference” can be quantified in terms of probability distributions. You can find a brief explanation of how this works here.
Differential privacy is an elegant and defensible solution to the problem of protecting personal privacy while also preserving the usefulness of data in the aggregate. But it’s also challenging to understand and implement. If you’re interested in exploring differential privacy for your business, let’s talk.
More differential privacy posts
- Protecting privacy while preserving dates
- Comparing truncation to differential privacy
- What is a privacy budget?
[1] You can see the search here. I’ve chopped off the vertical axis labels because they’re virtually meaningless. The proportion of occurrences of “differential privacy” among all two-word phrases is extremely small. But the rate of growth in the proportion is large.