Many Bayesian clinical trial methods have at their core a random inequality. Some examples from M. D. Anderson: adaptive randomization, binary safety monitoring, time-to-event safety monitoring. These method depends critically on evaluating P(X > Y) where X and Y are independent random variables. Roughly speaking, P(X > Y) is the probability that the treatment represented by X is better than the treatment represented by Y. In a trial with binary outcomes, X and Y may be the posterior probabilities of response on each treatment. In a trial with time-to-event outcomes, X and Y may be posterior probabilities of median survival time on two treatments.
People often have a little difficulty understanding what P(X > Y) means. What does it mean? If we take a sample from X and a random sample from Y, P(X >Y) is the probability that the former is larger than the latter. Most confusion around random inequalities comes from thinking of random variables as constants, not random quantities. Here are a couple examples.
First, suppose X and Y have normal distributions with standard deviation 1. If X has mean 4 and Y has mean 3, what is P(X > Y)? Some would say 1, because X is bigger than Y. But that’s not true. X has a larger mean than Y, but fairly often a sample from Y will be larger than a sample from X. P(X > Y) = 0.76 in this case.
Next, suppose X and Y are identically distributed. Now what is P(X > Y)? I’ve heard people say zero because the two random variables are equal. But they’re not equal. Their distribution functions are equal but the two random variables are independent. P(X > Y) = 1/2 by symmetry.
I believe there’s a psychological tendency to underestimate large inequality probabilities. (I’ve had several discussions with people who would not believe a reported inequality probability until they computed it themselves. These discussions are important when the decision whether to continue a clinical trial hinges on the result.) For example, suppose X and Y represent the probability of success in a trial in which there were 17 successes out of 30 on X and 12 successes out of 30 on Y. Using a beta distribution model, the density functions of X and Y are given below.
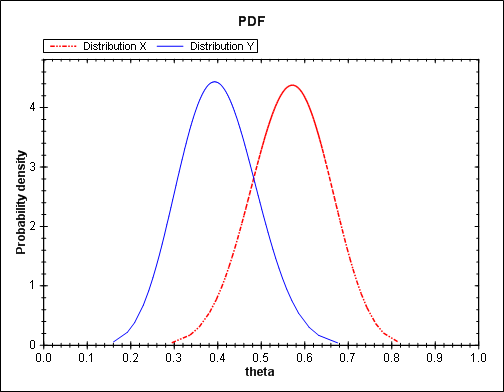
The density function for X is essentially the same as Y but shifted to the right. Clearly P(X > Y) is greater than 1/2. But how much greater than a half? You might think not too much since there’s a lot of mass in the overlap of the two densities. But P(X > Y) is a little more than 0.9.
The image above and the numerical results mentioned in this post were produced by the Inequality Calculator software.
Part II will discuss analytically evaluating random inequalities. Part III will discuss numerically evaluating random inequalities.
Basically, what you’re saying here is that people have a hard time understanding what the p in the p(..) means
John: I followed your link back to this post, and I’m glad I did – now I’m going to have to read the whole series. Good stuff!
When working with someone who is planning a study, we (statisticians) need some information about the mean and variance of the outcome to estimate a sample size. This is often difficult because most people don’t think about variance or variability. What I can do though is ask them to express the difference between two groups as the “odds” that given patient with treatment “A” will have a better outcome than a similar patient that receives treatment “B”. This is something clinicians understand and can usually answer readily. Given the odds (and a few assumptions) I can work out P[X>Y] (where X and Y are the outcomes for group A and B), and calculate power for a Chi-square test.
It’s not as good as having pilot data to calculate means and standard deviations, but expressing the clinical “inequality” of treatments as “odds” is a good place to start when no better information is available.
You said P(X > y) = 1/2 by symmetry.
I do not agree. You do not consider the cas P(X = Y) whose probability is non zero.
Isn’t it?
Anon: You are correct: in general P(X = Y) could be positive. I have implicitly assumed X and Y are continuous, and so P(X=Y) = 0, because in my work X and Y are always continuous.
How do you calculate P(X>Y)=0.76 ????
Khan: Please see the links at the bottom of the post. The Inequality Calculator is the software that calculated the number. The part III post describes the algorithm used in the software.
excellent links. I read in reverse order: numerical, analytical,definitions…and its works for me !!
do you know about any particular paper on psychological bias of large inequalities probabilities …. maybe some behavioural economics school paper
Sorry, I don’t know of any psychological studies along those lines.