How many?
The previous post showed how the number of Unicode characters has grown over time.
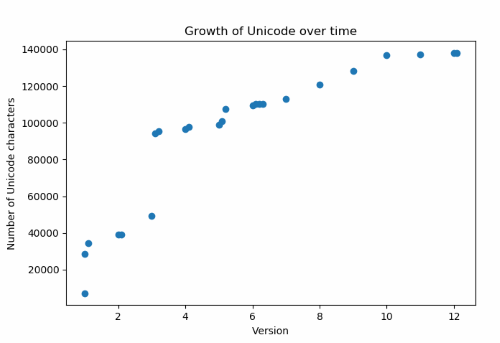
You’ll notice there was a big jump between versions 3.0 and 3.1. That will be important later on.
Unicode started out relative small then became much more ambitious. Are they going to run out of room? How many possible Unicode characters are there?
Short answer: There are 1,111,998 possible Unicode characters.
Longer answer: There are 17×216 − 2048 − 66 = 1,111,998 possible Unicode characters: seventeen 16-bit planes, with 2048 values reserved as surrogates, and 66 reserved as non-characters. More on this below.
Which ones?
Going one level of detail deeper, which numbers correspond to Unicode characters?
The hexadecimal numbers 0 through 10FFFF are potential Unicode characters, with exception of surrogates and non-characters.
Unicode is divided into 17 planes. The first two hexadecimal “digits” indicate the plane, and the last four indicate a value within the plane. The first plane is known as the BMP, the Basic Multilingual Plane. The rest are known as supplemental planes.
The surrogates are DC00 through DFFF and D800 through DBFF. The first range of 1024 surrogates are known as low surrogates, and the second rage of 1024 the high surrogates.
The non-characters are FDD0 through FDEF and the last two values in each plane: FFFE, FFFF, 1FFFE, 1FFFF, 2FFFE, 2FFFF, …, 10FFFE, 10FFFF. This is one range of 32 non-characters, plus 34 coming from the end of each plane, for a total of 66.
Why?
Why are there only 17 planes? And what are these mysterious surrogates and non-characters? What purpose do they serve?
The limitations of UTF-16 encoding explain why 17 planes and why surrogates. Non-characters require a different explanation.
UTF-16
This post mentioned at the top that the size of Unicode jumped between versions 3.0 and 3.1. Significantly, the size went from less than 216 to more than 216. Unicode broke out of the Basic Multilingual Plane.
Unicode needed a way to represent more than 216 characters using groups of 16 bits. The solution to this problem was UTF-16 encoding. With this encoding, the surrogate values listed above do not represent characters per se but are a kind of pointer to further values.
Sixteen supplemental planes would take 20 bits to describe, 4 to indicate the plane and 16 for the values within the plane. The idea was to use a high surrogate to represent the first 10 bits and a low surrogate to represent the last 10 bits. The values DC00 through DFFF and D800 through DBFF were unassigned at the time, so they were picked for surrogates.
In a little more detail, a character in one of the supplemental planes is represented by a hexadecimal number between 1 0000 and 10 FFFF. If we subtract off 1 0000 we get a number between 0000 and FFFFF, a 20-bit number. Take the first 10 bits and add them to D800 to get a high surrogate value. Take the last 10 bits and add them to DC00 to get a low surrogate value. This pair of surrogate values represents the value in one of the supplemental planes.
When you encounter a surrogate value, you don’t need any further context to tell what it is. You don’t need to look upstream for some indication of how the bits are to be interpreted. It cannot be a BMP character, and there’s no doubt whether it is the beginning or end of a pair of surrogate values since the high surrogates and low surrogates are in different ranges.
UTF-16 can only represent 17 planes, and the Unicode Consortium decided they would not assign values that cannot be represented in UTF-16. So that’s why there are 17 planes.
Non-characters
That leaves the non-characters. Why are a few values reserved to never be used for characters?
One use for non-characters is to return a null value as an error indicator, analogous to a NaN or non-a-number in floating point calculations. A program might return FFFF, for example, to indicate that it was unable to read a character.
Another use for special non-characters is to imply which encoding method is used. For reasons that are too complicated to get into here, computers do not always store the bytes within a word in the increasing order. In so called “little endian” order, lower order bits are stored before higher order bits. (“Big endian” and “little endian” are allusions to the two factions in Gulliver’s Travels that crack boiled eggs on their big end and little end respectively.)
The byte order mark FEFF is inserted at the beginning of a file or stream to imply byte ordering. If it is received in the order FEFF then the byte stream is inferred to be using the big endian convention. But if it is received in the order FFFE then little endian is inferred because FFFE cannot be a character.
The preceding paragraphs give a justification for at least two non-characters, FFFF and FFFE, but it’s not clear why 66 are reserved. There could be reasons for each plane would have its own FFFF and FFFE, which would account for 34 non-characters. I’m not clear on why FDD0 through FDEF are non-characters, though I vaguely remember there being some historical reason. In any case, people are free to use the non-characters however they see fit.
There are various byte-order masks like EF BB BF for UTF-8 (unused).
there are also composing characters, ie, how emoji can be different colors w/o having separate characters per-colored thingee.
Super content it was useful tnq
The historical reasons for assigning U+FDD0..FDEF are in the Unicode FAQ, although they don’t explain how “the need for more BMP noncharacters became apparent”: http://www.unicode.org/faq/private_use.html#nonchar4b
Thanks, nice post
> There are various byte-order masks like EF BB BF for UTF-8 (unused).
Actually, this is just the UTF-8 encoding of U+FEFF.
I’ll represent the bit patterns as pattern/mask for readability (10xxxxxx = 80/3F)
FEFF is between 800 and FFFF, putting it in the 3-byte range, so it’ll be stored in 3 bytes E0/0F 80/3F 80/3F
FE/F0 into E0/0F = EF (1110-1111)
FEFF/0FC0 into 80/3F = BB (10-11-1011)
FF/30 into 80/3F = BF (10-11-1111)
Byte order marks have no meaning in UTF-8, and are interpreted as normal characters. In U+FEFF’s case, a zero-width no-break space.
I’d imagine the noncharacters at the end of each plane are there so that there’s compatibility across UTF-16 and UTF-32 (and so the ISO 10646 repertoire) wrt the error codepoint and the byte order mark. Remember endianness is even worse of a problem with the original 32 bit encoding used on the ISO side, before it was coordinated with Unicode Consortium’s efforts.
The need for extra noncharacters is documented in the FAQ, if opaquely. Most often they are used as part of Unicode normalization and collation algorithms, as sentinels within sorting routines. Since such sorting goes on at quite a number of levels, in order to get the job done with a single sorting pass, a number of sentinels with different values are used to demark the levels.