Suppose you have a database of personally identifiable information (PII) and you want to allow someone else to query the data while protecting the privacy of the individuals represented by the data. There are two approaches:
- Deidentify, then query
- Query, then deidentify
The first approach is to do whatever is necessary to deidentify the data—remove some fields, truncate or randomize others, etc.—and then pose a query to this redacted data.
The second approach is to query the original data, then do whatever is necessary to deidentify the results.
In graphical terms, you can get from raw data to a deidentified result either by following the green arrows or the blue arrows below. In mathematical terms, this diagram does not commute.
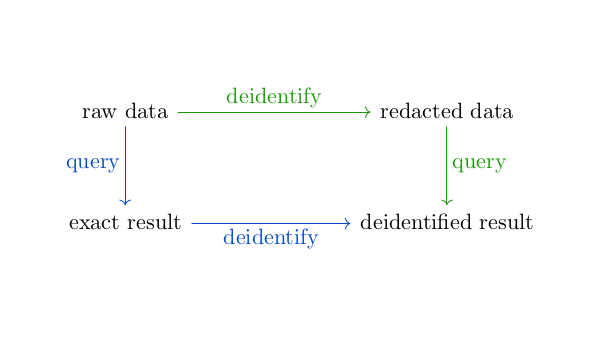
The first approach is most common. A company that owns data (a “covered entity” in HIPAA terms) will deidentify it and license it to another company who then queries it. The second approach is becoming more common, where a company will license access to querying their data.
Pros and cons
Which approach is better? If by better you mean more accurate results, it’s always best to query first then deidentify. The order in which you do things matters, and deidentifying as late as possible preserves information.
The situation is analogous to carrying out a sequence of steps on a calculator. If you want your final result to be accurate to two decimal places, you first carry out all your operations to as much precision as you can, then round the final result. If you round your numbers first, you probably will get less accurate results, maybe even useless results.
However, deidentifying data before querying it is better in some non-mathematical ways. Data scientists want the convenience of working with the data with their tools in their environment. They want to possess (a deidentified version of) the data rather than have access to query the (exact) data. They also want the freedom to run ad hoc queries [1].
There are logistical and legal details to work out in order to license access to query data rather than licensing the data. But it is doable, and companies are doing it.
Why query first
When you deidentify data first, you have to guard against every possible use of the data. But when you deidentify data last, you only have to guard against the actual use of the data.
For example, suppose you are considering creating a new clinic and you would like to know how many patients of a certain type live closer to the location you have in mind than the nearest alternative. A data vendor cannot give you exact locations of patients. If they were to release such data, they’d have to obscure the addresses somehow, such as giving you the first three digits of zip codes rather than full addresses. But if you could ask your query of someone holding the full data, they may tell you exactly what you want to know.
Some queries may pose no privacy risk, and the data holder can return exact results. Or they may need to jitter the result a bit in order to protect privacy, for reasons explained here. But it’s better to jitter an exact result than to jitter your data before computing.
How to query first
The query-first approach requires a trusted party to hold the unredacted data. There are a variety of ways the data holder can license access, from simple to sophisticated, and in between.
The simplest approach would be for the data holder to sell reports. Maybe the data holder offers a predetermined set of reports, or maybe they allow requests.
The most sophisticated approach would be to use differential privacy. Clients are allowed to pose any query they wish, and a query manager automatically adds an amount of randomness to the results in proportion to the sensitivity of the query. All this is done automatically according to a mathematical model of privacy with no need for anyone to decide a priori which queries will be allowed.
There are approaches conceptually between pre-determined reports and differential privacy, offering more flexibility than the former and being easier to implement than the latter. There’s a lot of room for creativity in this space.
Related posts
[1] Being able to run ad hoc queries with no privacy budget is certainly simpler, in the same way that an all-you-can-eat buffet is simpler than ordering food à la carte. But it also means the price is higher. Deidentifying an entire data set entails more loss of accuracy that deidentifying a set of queries.