The previous post looked at the Bitcoin network hash rate, currently around one zettahash per second, i.e. 1021 hashes per second. The difficulty of mining a Bitcoin block adjusts over time to keep the rate of block production relatively constant, around one block every 10 minutes. The plot below shows this in action.
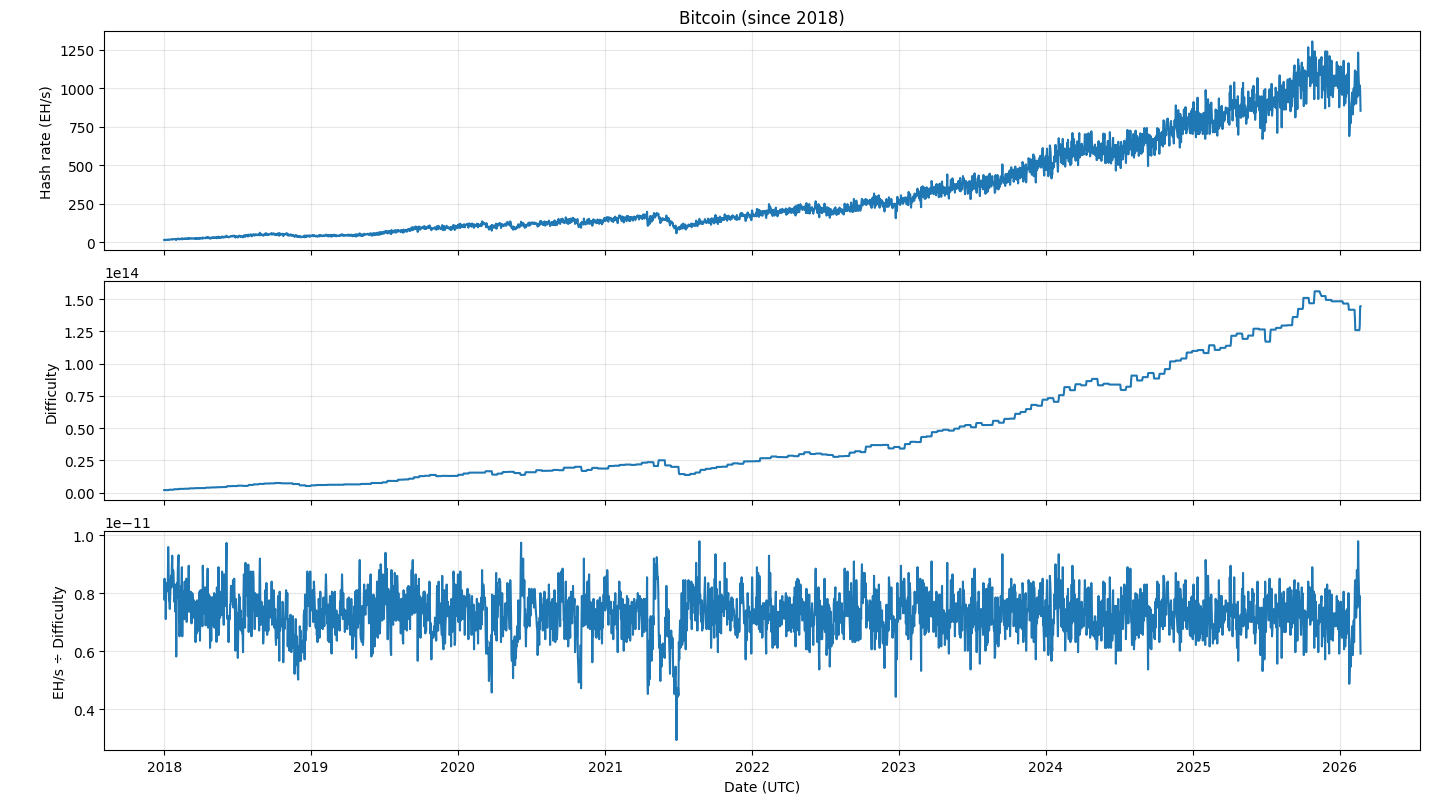
Notice the difficulty graph is more quantized than the hash rate graph. This is because the difficulty changes every 2,016 blocks, or about every two weeks. The number 2016 was chosen to be the number of blocks that would be produced in two weeks if every block took exactly 10 minutes to create.
The ratio of the hash rate to difficulty is basically constant with noise. The noticeable dip in mid 2021 was due to China cracking down on Bitcoin mining. This caused the hash rate to drop suddenly, and it took a while for the difficulty level to be adjusted accordingly.
Mining difficulty
At the current difficulty level, how many hashes would it take to mine a Bitcoin block if there were no competition? How does this compare to the number of hashes the network computes during this time?
To answer these questions, we have to back up a bit. The current mining difficulty is around 1014, but what does that mean?
The original Bitcoin mining task was to produce a hash [1] with 32 leading zeros. On average, this would take 232 attempts. Mining difficulty is defined so that the original mining difficult was 1 and current mining difficulty is proportional to the expected number of hashes needed. So a difficulty of around 1014 means that the expected number of hashes is around
1014 × 232 = 4.3 × 1023.
At one zetahash per second, the number of hashes computed by the entire network over a 10 minute interval would be
1021 × 60 × 10 = 6 × 1023.
So the number of hashes computed by the entire network is only about 40% greater than what would be necessary to mine a block without competition.
Related posts
- What exactly is the Bitcoin proof-of-work task?</a?
- Hashing names does not adequately protect privacy
- Blockchains and cryptocurrencies
[1] The hash function used in Bitcoin’s proof of work is double SHA256, i.e. the Bitcoin hash of x is SHA256( SHA256( x ) ). So a single Bitcoin hash consists of two applications of the SHA256 hash function.