A few days ago I wrote a post comparing English and Japanese vowel sounds in a 2D chart. In this post I’d like to do something similar for English and Swedish. As before the data come from [1].
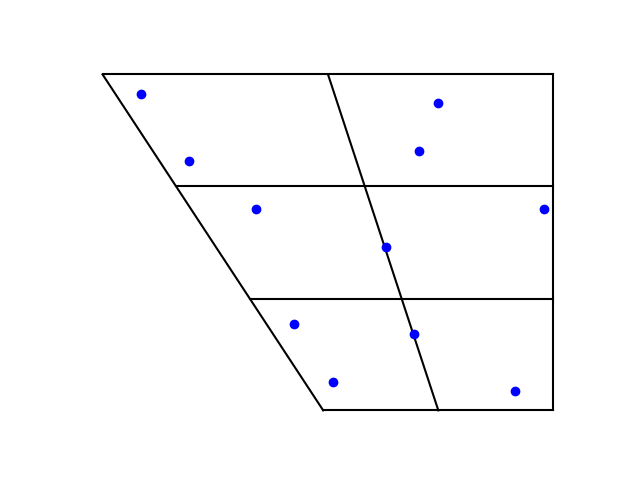
A friend of mine who learned Swedish would joke about how terribly he had to contort his mouth to speak the language. Swedish vowels are objectively difficult for non-native speakers as can be seek in a vowel chart. The vertical axis runs from closed sounds on top to open sounds on the bottom. The horizontal axis runs from front vowels on the left to back vowels on the right.
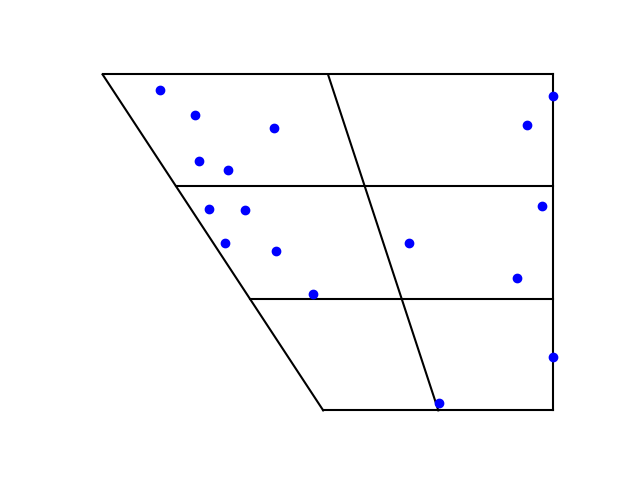
There are a lot of vowel sounds, and many of them are clustered close together. Japanese, by contrast, has only five vowel sounds, and they’re widely spread apart.
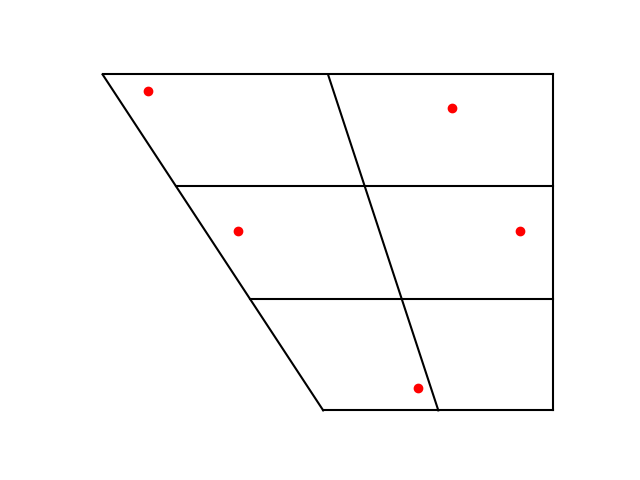
The vowel charts for Spanish and Hebrew look fairly similar to the chart for Japanese above: five vowels spread out in roughly the same locations.
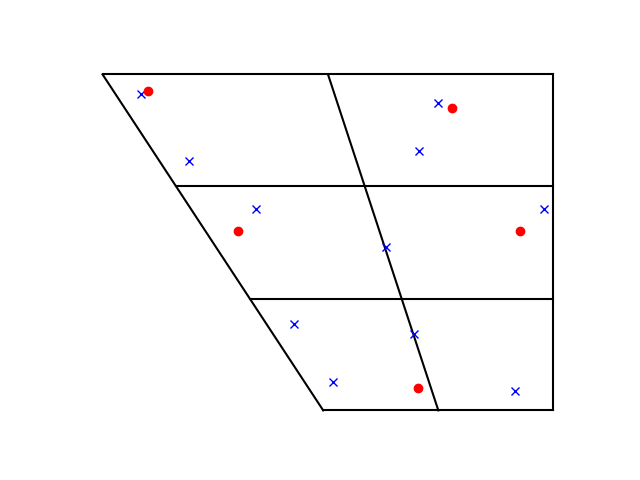
It wouldn’t matter so much that Swedish has a lot of tightly clustered vowel sounds if your native language has the same sounds, but the following chart shows that English and Swedish vowels are quite different. The red x’s mark English vowel locations and the blue dots mark Swedish vowels.
[1] Handbook of the International Phonetic Association: A Guide to the Use of the International Phonetic Alphabet. Cambridge University Press, 2021.