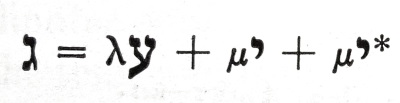In this post I interview Greg Greenlaw, a friend of mine who served as a missionary to the Nakui tribe in Papua New Guinea and developed their writing system. (Nakui is pronounced like “knock we.”)
JC: When you went to PNG to learn Nakui was there any writing system?
GG: No, they had no way of writing words or numbers. They had names for only seven numbers — that was the extent of their counting system — but they could coordinate meetings more than a few days future by tying an equal number of knots in two vines. Each party would take a vine with them and loosen a knot each morning until they counted down to the appointed time — like and advent calendar, but without numbers!
JC: I believe you said that Nakui has a similar grammar to other languages in PNG but completely different vocabulary. Were you able to benefit from any other translation work in the area? Will your work serve as a starting point for translating another language?
GG: Yes. Missionaries had moved into our general area back in the 80s and the languages they studied had mostly the same grammar features that we saw in the Nakui language. This sped the process, but in truth, the slowest part of learning to speak was not analyzing the grammar, it was training yourself to use it. Each Nakui verb could conjugate 300 different ways depending on person, recipient, tense, aspect, direction, and number.
JC: Do any of the Nakui speak a pidgin or any other language that served as a bridge for you to learn their language?
GG: We were blessed with one very good pidgin speaker when we moved into the village and several others who spoke the Melanesian Tok Pisin at a moderate level. That was a help in eliciting phrases and getting correction, but there were limits to how much they understood about their own speech. They had never thought about their language analytically and could not state a reason for the different suffixes used in the language, they just knew it was the right way to say something. Most peculiar was that they couldn’t even tell where certain word breaks were. Their language had never been “visible” to them. Nouns were easy to separate out, but it was hard to know if certain modifiers were affixes or separate function words.
JC: What are a few things that English speakers would find surprising about the language?
GG: Nakui has very few adjectives but innumerable verbs. They do the majority of their describing by using a very specific verb. There is a different verb for cutting something in the middle as opposed to cutting off a small section or cutting it long ways or cutting something to fall downward or cutting something to bits. The correct verb for the situation will also depend on the object being cut — is it log-like, leaf-like, or flesh-like.
JC: Do you try to learn a new language aurally first before starting on a writing system, or do you start developing a writing system early on so you can take notes?
GG: It’s language, so you always want your ears and tongue to lead your eyes. We use the international phonetic alphabet to write down notes, but we encourage language learners to hold off on writing anything for almost a month. After they are memorizing and pronouncing correctly a host of nouns and some noun modifiers, then we encourage them to start writing down their data with the phonetic alphabet. About half way to fluency they usually have enough perspective on the variety of sounds and where those sounds occur that they can narrow down a useful alphabet.
JC: How long did it take to learn the language? To create the writing system? How many people were working on the project?
GG: Primarily Tim Askew and myself, but there were three other missionaries that worked among the Nakui in the early days and each had some contribution to our understanding. The biggest credit really belongs to God, by whose grace we were allowed to live there and by whose strength we were able to chip away for three years until the job was done.
JC: Can you describe the process you went through to create the writing system?
GG: Well after collecting thousands of words written phonetically we could start a process of regularizing all that data. Looking at the language as a whole we had to decided the sleekest, most uniform way to consistently spell those sounds phonetically. After cleaning up our data we could take a hard look at which of the sounds were unique and which are just modified by surrounding sounds. Phonetically the English language has three different ‘t’ sounds: an aspirated ‘t’, and unaspirated ‘t’, and an unreleased ‘t’. We only think of one ‘t’ sound, though, and it would be confusing (and irritating) if we had three ‘t’ symbols in our alphabet. Our ‘t’s just become unreleased automatically when they are at the end of a word and they become unaspirated when they blend with an ‘s’. You need to narrow down the number of sounds to just the ones that are significant and meaningful. It is only those unique sounds that are given letters in the alphabet.
JC: What is the alphabet you settled on? Do the letters represent sounds similar to what an English speaker would expect?
GG: We found 10 vowel sounds and 10 consonant sounds were needful in the Nakui language. The 10 consonants are symbolized the same as English, but the vowels had to be augmented. We borrowed the letter ‘v’ to become the short ‘u’ sound and used accent marks over other vowels to show their lowered and more nasalized quality.
JC: Could you give an example of something written in Nakui?
GG: This is John 3:16. Músvilv Sisasvyv me iyemvi, “Kotvlv asini niyanú nonú mvli mvlei ufau. Múmvimvilv, tuwani aluwalv siyv tuwayv itii, asinosv. Mvimeni notalv me svmvleliyelv, ‘Sisasvni yáfu kokuimvisv,’ múmeni nonv ba itinvini, i tínonvminvini.
JC: Is it unusual for a language to have as many vowel symbols as consonant symbols?
GG: Good question. I’m not sure what normal would be worldwide, but I know we have a lot more than five vowel sounds in English! All our English vowel symbols have double or triple allophones (long sounds, short sounds, alternate sounds) making it very challenging to instruct my 6 yr old in the skill of reading.
JC: Have you published anything on your work, say in a linguistics journal?
GG: No, there is nothing unique in what we did. Truth is, we organized our findings and reported our work in an informal, non-academic, pragmatic way because our goal was not a PhD in anthropology, but a redeeming ministry in the lives of tribal men and women and ultimately a commendation from the Maker of men.
JC: How many of the Nakui can read their language?
GG: All the young men in our village are readers now, with the exception of a dyslexic man who attempted our literacy course three times without result. About 1/3 of the young women can read. They have less available time for study, and in the early days the village leaders did not allow the girls to be in class with the boys. As a result, literacy for ladies had a slower start and fewer participants. There were older men who tried to learn to read, but none that succeeded. The gray matter seemed to have stiffened.
JC: If English didn’t have a writing system and you were designing one from scratch, what would you do differently?
GG: Wow, we have six kids we’ve taught to read – we would do a lot differently! The ideal is to have one symbol for each meaningful sound in the language. English would need more vowels and fewer consonants. Life would actually be more pleasant without ‘c’, ‘j’, ‘q’ and ‘x’. If you removed those and added about six vowels we could come up with a spelling system that was predictable and easy to learn.
JC: Anything else you’d like to say?
GG: One of the most remarkable things about the Nakui language is how sophisticated and complex it is. Unblended with other languages, it is extremely consistent in its grammar. Although it is in a constant state of change (rapid change relative to written languages of the world), it remains organized. This order is not to the credit of the society that speaks it, it happens utterly in spite of them. They are completely unaware of the structure of their own grammar and are perhaps the most disorderly people on the planet. The aspects of life over which they hold sway are corrupt and miserable, but in this small, unmanaged area of their lives, a glimpse of the divine still peeks out. The God of order, who created them in His own image, gave them an innate ability to communicate complex ideas in and orderly way. Like Greek, they specify singular, dual and plural. They have six tenses (English has only three), and 11 personal pronouns (English has only six). Every verb is conjugated to carry this specificity with extreme consistency. The verb to ‘go’ is the only irregular verb in the whole Nakui language. English, although vast, is a disheveled mess compared to what is spoken by these stone age people in the swamps of interior New Guinea.
Related posts