I needed to know the frequencies of letters at the beginning of words for a project. The overall frequency of letters, wherever they appear in a word, is well known. Initial frequencies are not so common, so I did a little experiment.
I downloaded the Canterbury Corpus and looked at the frequency of initial letters in a couple of the files in the corpus. I first tried a different approach, then realized a shell one-liner [1] would be simpler and less-error prone.
cat alice29.txt | lc | grep -o '\b[a-z]' | sort | uniq -c | sort -rn
This shows that the letters in descending order of frequency at the beginning of a word are t, a, s, …, j, x, z.
The file alice29.txt is the text of Alice’s Adventures in Wonderland. Then for comparison I ran the same script on another file, lcet10.txt. a lengthy report from a workshop on electronic texts.
This technical report’s initial letter frequencies order the alphabet t, a, o, …, y, z, x. So starting with the third letter, the two files have different initial letter frequencies.
I made the following plot to visualize how the frequencies differ. The horizontal axis is sorted by overall letter frequency (based on the Google corpus summarized here).
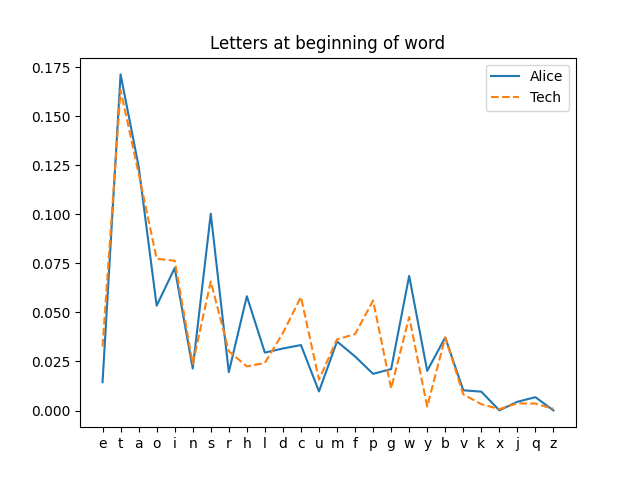
I expected the initial letter frequencies to differ from overall letter frequencies, but I did not expect the two corpora to differ.
Apparently initial letter frequencies vary more across corpora than overall letter frequencies. The following plot shows the overall letter frequencies for both corpora, with the horizontal axis again sorted by the frequency in the Google corpus.
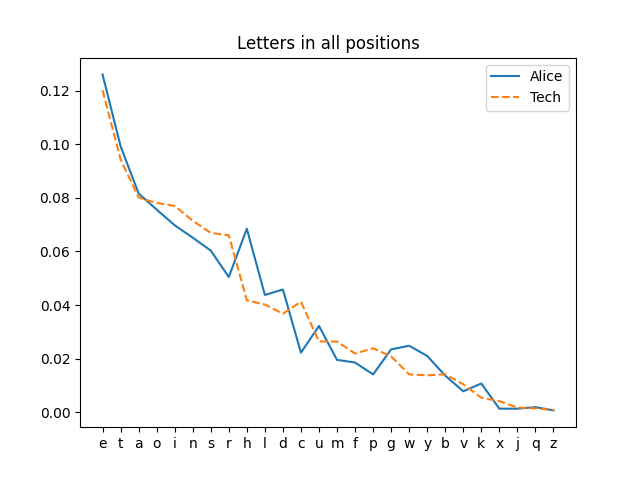
Here the two corpora essentially agree with each other and with the Google corpus. The tech report ranks letters in essentially the same order as the Google corpus because the orange dashed line is mostly decreasing, though there is a curious kink in the graph at c.
Related posts
[1] The lc function converts its input to lower case. See this post for how to install and use the function.
Table 3-1 (p39) of Bourne’s excellent “Methods of Information Handling” (1963) is titled “Comparative Ranking by Frequency of Occurrence of Initial Letters in English Words”, with results from 5 earlier publications; two for “subject words” and three for “continuous text”.
If you have an archive.org account you can check out the book and see the page at https://archive.org/details/methodsofinforma0000unse/page/38/mode/2up .
The three ‘continuous text’ citations are from the 1930s and 1940s and would certainly have involved a lot more work than your one-liner. The Smith citation’s table is https://archive.org/details/cryptography-the-science-of-secret-writing-laurence-d.-smith/page/152/mode/2up .
Two possible reasons why the initial letter frequencies differ more among corpora than the overall letter frequencies:
1) There is likely to be some variation among letter frequencies, even among similar works. If two corpora consisted of letters chosen at random from the same distribution, we would expect to see more of a difference between the initial letter frequencies than the overall letter frequencies, because the sample size is smaller (there are obviously more overall letters than initial letters).
2) A significant portion of the letters in any given work probably comes from a small number of words. For example, Alice in Wonderland probably has a much higher frequency of “Alice” than the English language as a whole. Imagine for a moment that two works have an average word length of 5 and are identical except that, in one of them, 1% of the words are replaced with “Alice”. Then the frequencies of initial letters differ by almost 1% for one letter and a small amount for the others, and the frequencies of overall letters differ by almost 0.2% for five letters and a small amount for the others. The former is likely more noticeable.
“A significant portion of the letters in any given work probably comes from a small number of words.”
Yes. This is probably common, since different subject matter involves a different vocabulary. The folks who try to figure out how large people’s vocabularies are, found that blokes who wrote more stuff seem to have larger vocabularies because each new thing they write talks about different things. For example, Shakespeare has a “vocabulary size” proportional to how many of his works you count the words in.
Huffman Coding is based on letter counting as well. I wrote a Huffman code compressor program in FORTRAN 77 long ago for a communication challenge between two flying devices for the USAF
You post brought back memories of a simpler time