Swish, mish, and serf are neural net activation functions. The names are fun to say, but more importantly the functions have been shown to improve neural network performance by solving the “dying ReLU problem.” This happens when a large number of node weights become zero during training and do not contribute further to the learning process. The weights may be “trying” to be negative, but the activation function won’t allow it. The swish family of activation functions allows weights to dip negative.
Softplus can also be used as an activation function, but our interest in softplus here is as part of the definition of mish and serf. Similarly, we’re interested in the sigmoid function here because it’s used in the definition of swish.
Softplus, softmax, softsign
Numerous functions in deep learning are named “soft” this or that. The general idea is to “soften” a non-differentiable function by approximating it with a smooth function.
The plus function is defined by
![]()
In machine learning the plus is called ReLU (rectified linear unit) but x+ is conventional mathematical notation.
The softplus function approximates x+ by
![]()
We can add a parameter to the softplus function to control how soft it is.
![]()
As the parameter k increases, softmax becomes “harder.” It more closely approximates x+ but at the cost of the derivative at 0 getting larger.
We won’t need other “soft” functions for the rest of the post, but I’ll mention a couple more while we’re here. Softmax is a smooth approximation to the max function
![]()
and softsign is a smooth approximation to the sign function.
![]()
which is differentiable at the origin, despite the absolute value in the denominator. We could add a sharpness parameter k to the softmax and softsign functions like we did above.
Sigmoid
The sigmoid function, a.k.a. the logistic curve, is defined by
![]()
The second and third expressions are clearly equal, but I prefer to think in terms of the former, but the latter is better for numerical calculation because it won’t overflow for large x.
The sigmoid function is the derivative of the softplus function. We could define a sigmoid function with a sharpness parameter k by taking the derivative of the softplus function with sharpness parameter k.
Swish
The Swish function was defined in [1] as
![]()
Like softplus, the Swish function is asymptotically 0 as x → −∞ and asymptotically equal to x as x → ∞. That is, for large |x|, swish(x) is approximately x+. However, unlike softplus, swish(x) is not monotone. It is negative for negative x, having a minimum around -1.278 [2]. The fact that the activation function can dip into negative territory is what addresses “the dying ReLU problem,”
Mish
The Mish function was defined in [3] as
![]()
The mish function has a lot in common with the swish function, but performs better, at least on the examples the author presents.
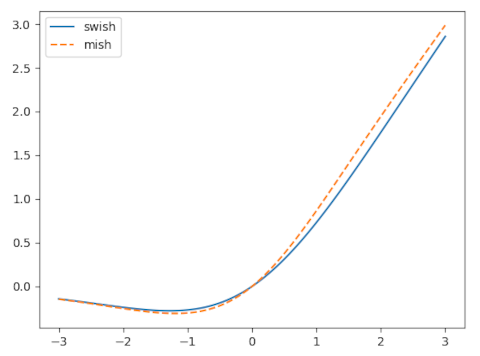
The mish function is said to be part of the swish function family, as is the serf function below.
Serf
The serf function [4] is another variation on the swish function with similar advantages.
![]()
The name “serf” comes from “log-Softplus ERror activation Function” but I’d rather pronounce it “zerf” from “x erf” at the beginning of the definition.
The serf function is hard to distinguish visually from the mish function; I left it out of the plot above to keep the plot from being cluttered. Despite the serf and mish functions being close together, the authors in [4] says the former outperforms the latter on some problems.
Numerical evaluation
The most direct implementations of the softplus function can overflow, especially when implemented in low-precision floating point such as 16-bit floats. This means that the mish and serf functions could also overflow.
For large x, exp(x) could overflow, and so computing softplus as
log(1 + exp(x))
could overflow while the exact value would be well within the range of representable numbers. A simple way to fix this would be to have the softmax function return x when x is so large that exp(x) would overflow.
As mentioned above, the expression for the sigmoid function with exp(-x) in the denominator is better for numerical work than the version with exp(x) in the numerator.
Related posts
[1] Swish: A Self-Gated Activation Function. Prajit Ramachandran∗, Barret Zoph, Quoc V. arXiv:1710.05941v1
[2] Exact form of the minimum location and value in terms of the Lambert W function discussed in the next post.
[3] Mish: A Self Regularized Non-Monotonic Activation Function. Diganta Misra. arXiv:1908.08681v3
[4] SERF: Towards better training of deep neural networks using log-Softplus ERror activation Function. Sayan Nag, Mayukh Bhattacharyya. arXiv:2108.09598v3
It would be nice if you could add a paragraph describing the “dying ReLU problem” nd how these activation functions prevent it from happening.