Roll five dice and use the sum to simulate samples from a normal distribution. This is an idea I ran across in Teaching Statistics by Andrew Gelman and Deborah Nolan. The book mentions this idea in the context of a classroom demonstration where students are to simulate IQ scores.
I was surprised that just five dice would do a decent job. So just how good a job does the dice generator do?
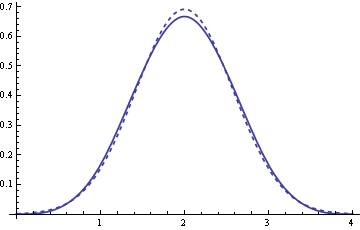
To find out, I looked at the difference between the cumulative densities of the dice generator and an exact normal generator. When you roll a single six-sided die, the outcomes have mean 3.5 and variance 35/12, and so the corresponding mean and variance for rolling 5 dice is 5 times greater. By the central limit theorem, the sum of the five rolls should have approximately the same distribution as a normal random variable with the same mean and variance. So what we want to do is compare the distribution of the sum of the five dice rolls to a Normal(17.5, 3.8192).
Now how do we get the distribution of the sum of the five dice? For one die it’s easy: the numbers 1 through 6 all have probability 1/6 of showing up. The sum of two dice is harder, but not too hard to brute force. But if you’re looking at five or more dice, you need to be a little clever.
By using generating functions, you can see that the probability of getting a sum of k spots on the five dice is the coefficient of xk in the expansion of
(x + x2 + x3 + x4 + x5 + x6)5 / 65
In Mathematica code, the probability density for the sum of the five dice is
pmf = Table[
6^-5 Coefficient[(x + x^2 + x^3 + x^4 + x^5 + x^6)^5, x^i],
{i, 30}]
To get the distribution function, we need to create a new list whose nth item is the sum of the first n items in the list above. Here’s the Mathematica code to do that.
cdf = Rest[FoldList[Plus, 0, pmf]]
The FoldList repeatedly applies the function supplied as its first argument, in this case Plus, starting with the second argument, 0. The Rest function removes the extra 0 that FoldList adds to the front of the list. (Like cdr for Lisp fans.)
Here’s the Mathematica code to produce the corresponding normal distribution.
norm = Table[
CDF[NormalDistribution[3.5*5, Sqrt[5*35/12]], i],
{i, 30}]
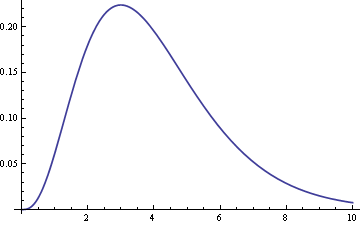
Here’s what the difference between the dice distribution and the normal distribution looks like:
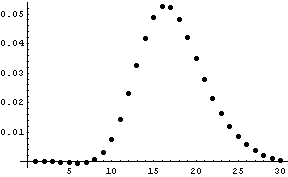
The maximum error is about 5%. It’s not an industrial quality random number generator, but it’s perfectly adequate for classroom demonstrations.
Now what would happen if we rolled more than five dice? We’d expect a better approximation. In fact, we can be more precise. The central limit theorem suggests that as we roll n dice, the maximum error will be proportionate to 1/√ n when n is large. So if we roll four times as many dice, we’d expect the error to go down by a factor of two. In fact, that’s just what we see. When we go from 5 dice to 20 dice, the maximum error goes from 0.0525 to 0.0262.