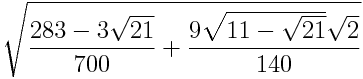“Nothing brings fear to my heart more than a floating point number.” — Gerald Jay Sussman
The context of the above quote was Sussman’s presentation We really don’t know how to compute. It was a great presentation and I’m very impressed by Sussman. But I take exception to his quote.
I believe what he meant by his quote was that he finds floating point arithmetic unsettling because it is not as easy to rigorously understand as integer arithmetic. Fair enough. Floating point arithmetic can be tricky. Things can go spectacularly bad for reasons that catch you off guard if you’re unprepared. But I’ve been doing numerical programming long enough that I believe I know where the landmines are and how to stay away from them. And even if I’m wrong, I have bigger worries.
Nothing brings fear to my heart more than modeling error.
The weakest link in applied math is often the step of turning a physical problem into a mathematical problem. We begin with a raft of assumptions that are educated guesses. We know these assumptions can’t be exactly correct, but we suspect (hope) that the deviations from reality are small enough that they won’t invalidate the conclusions. In any case, these assumptions are usually far more questionable than the assumption that floating point arithmetic is sufficiently accurate.
Modeling error is usually several orders of magnitude greater than floating point error. People who nonchalantly model the real world and then sneer at floating point as just an approximation strain at gnats and swallow camels.
In between modeling error and floating point error on my scale of worries is approximation error. As Nick Trefethen has said, if computers were suddenly able to do arithmetic with perfect accuracy, 90% of numerical analysis would remain important.
To illustrate the difference between modeling error, approximation error, and floating point error, suppose you decide that the probability of something can be represented by a normal distribution. This is actually two assumptions: that the process is random, and that as a random variable it has a normal distribution. Those assumptions won’t be exactly true, so this introduces some modeling error.
Next we have to compute something about a normal distribution, say the probability of a normal random variable being in some range. This probability is given by an integral, and some algorithm estimates this integral and introduces approximation error. The approximation error would exist even if the steps in the algorithm could be carried out in infinite precision. But the steps are not carried out with infinite precision, so there is some error introduced by implementing the algorithm with floating point numbers.
For a simple example like this, approximation error and floating point error will typically be about the same size, both extremely small. But in a more complex example, say something involving a high-dimensional integral, the approximation error could be much larger than floating point error, but still smaller than modeling error. I imagine approximation error is often roughly the geometric mean of modeling error and floating point error, i.e. somewhere around the middle of the two on a log scale.
In Sussman’s presentation he says that people worry too much about correctness. Often correctness is not that important. It’s often good enough to produce a correct answer with reasonably high probability, provided the consequences of an error are controlled. I agree, but in light of that it seems odd to be too worried about inaccuracy from floating point arithmetic. I suspect he’s not that worried about floating point and that the opening quote was just an entertaining way to say that floating point math can be tricky.
More on floating point computing