My interest in cryptocurrency is primarily technical, and privacy coins are the most technically interesting. The math behind coins like Monero and Zcash is far more sophisticated than the math behind Bitcoin.
I’m also interested in the privacy angle since I work in data privacy. The zero-knowledge proof (ZKP) technology developed for and tested in privacy coins is applicable outside of cryptocurrency.
I don’t follow the price of privacy coins, but I heard about the price of Zcash doubling recently.
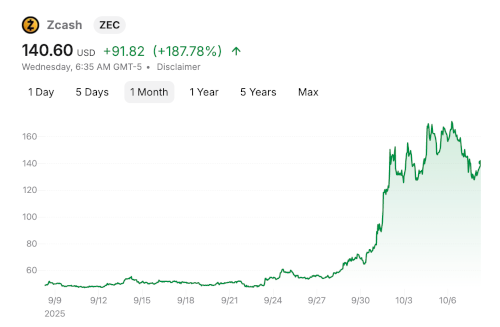
I’d like to understand why that happened, especially why it happened so suddenly, though I’m very skeptical of post hoc explanations of price changes. I roll my eyes when I hear reporters say the stock market moved up or down by some percent because of this or that event. Any explanation for the aggregate behavior of a complex system that fits into sound byte is unlikely to contain more than a kernel of truth.
Naval Ravikant said on October 1
Bitcoin is insurance against fiat.
ZCash is insurance against Bitcoin.
This was after Zcash had started rising, so Naval’s statement wasn’t the cause of the rise. But the idea behind his statement was in the air before he crystalized it. Maybe the recent increase in the price of Bitcoin led to the rise of Zcash as a hedge against Bitcoin falling. It’s impossible to know. Traders don’t fill out questionnaires explaining their motivations.
It has been suggested that more people are interested in using Zcash as a privacy-preserving currency, not just buying it for financial speculation. It’s plausible that this could be a contributing factor in the rise of Zcash, though interest in financial privacy is unlikely to spike over the course of one week, barring something dramatic like FDR’s confiscation of private gold in 1933.
The price of Monero increased along with Zcash, though not as by nearly as much.
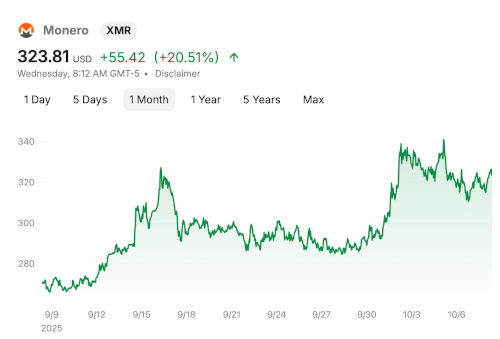
This suggests there may be increased interest in privacy coins more generally and not just in Zcash.
It would be interesting to see how people are using Zcash and Monero—how much is being spent on goods and services and how much is just being traded as an investment—but this would be difficult since privacy coins obscure the details of transactions by design.



