A few days ago I wrote about testing the PCG random number generator using the DIEHARDER test suite. In this post I’ll go into a little more background on this random number generator test suite. I’ll also show that like M. E. O’Neill’s PCG (“permuted congruential generator”), George Marsaglia’s MWC (“multiply with carry”) generator does quite well.
This is not to say that MWC is the best generator for every purpose, but any shortcomings of MWC are not apparent from DIEHARDER. The PCG family of generators, for example, is apparently superior to MWC, but you couldn’t necessarily conclude that from these tests.
Unless your application demands more of a random number generator than these tests do, MWC is probably adequate for your application. I wouldn’t recommend it for cryptography or for high-dimensional integration by darts, but it would be fine for many common applications.
DIEHARDER test suite
George Marsaglia developed the DIEHARD battery of tests in 1995. Physics professor Robert G. Brown later refined and extended Marsaglia’s original test suite to create the DIEHARDER suite. (The name of Marsaglia’s battery of tests was a pun on the Diehard car battery. Brown continued the pun tradition by naming his suite after Die Harder, the sequel to the movie Die Hard.) The DIEHARDER suite is open source. It is designed to be at least as rigorous as the original DIEHARD suite and in some cases more rigorous.
There are 31 distinct kinds of tests in the DIEHARDER suite, but some of these are run multiple times. In total, 114 tests are run.
Marsaglia’s MWC
The main strength of Marsaglia’s MWC algorithm is that it is very short. The heart of the code is only three lines:
m_z = 36969 * (m_z & 65535) + (m_z >> 16);
m_w = 18000 * (m_w & 65535) + (m_w >> 16);
return (m_z << 16) + m_w;
The heart of PCG is also very short, but a bit more mysterious.
rng->state = oldstate * 6364136223846793005ULL + (rng->inc | 1);
uint32_t xorshifted = ((oldstate >> 18u) ^ oldstate) >> 27u;
uint32_t rot = oldstate >> 59u;
return (xorshifted >> rot) | (xorshifted << ((-rot) & 31));
(These are the 64-bit state versions of MWC and PCG. Both have versions based on larger state.)
Because these generators require little code, they’d be relatively easy to step into with a debugger, compared to other RNGs such as Mersenne Twister that require more code and more state.
Test results
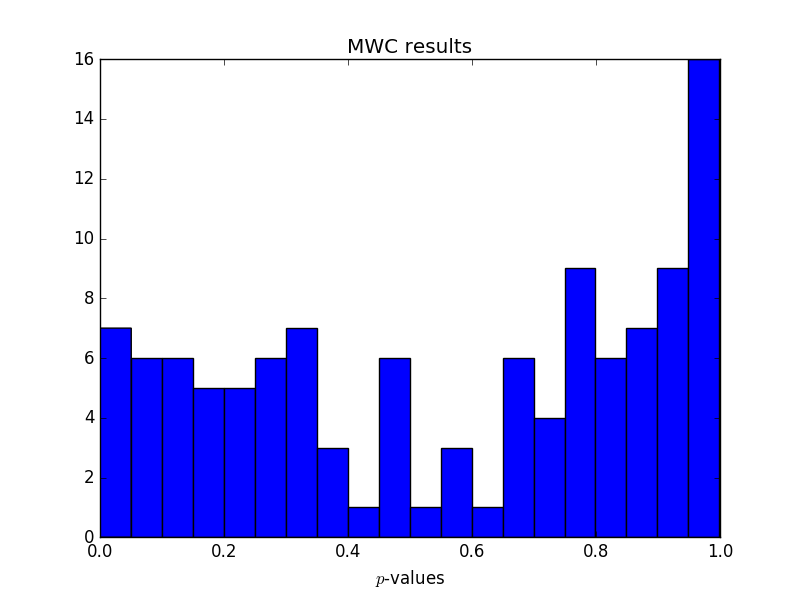
Out of the 114 DIEHARDER tests run on MWC, all but three returned a pass, and the rest returned a weak pass.
A few weak passes are to be expected. The difference between pass, weak pass, and failure is whether a p-value falls below a certain threshold. Theory says that ideally p-values would uniformly distributed, and so one would fall outside the region for a strong pass now and then.
Rather than counting strong and weak passes, let’s look at the p-values themselves. We’d expect these to be uniformly distributed. Let’s see if they are.
Here are the p-values reported by the DIEHARDER tests for MWC:
Here are the corresponding values for PCG:
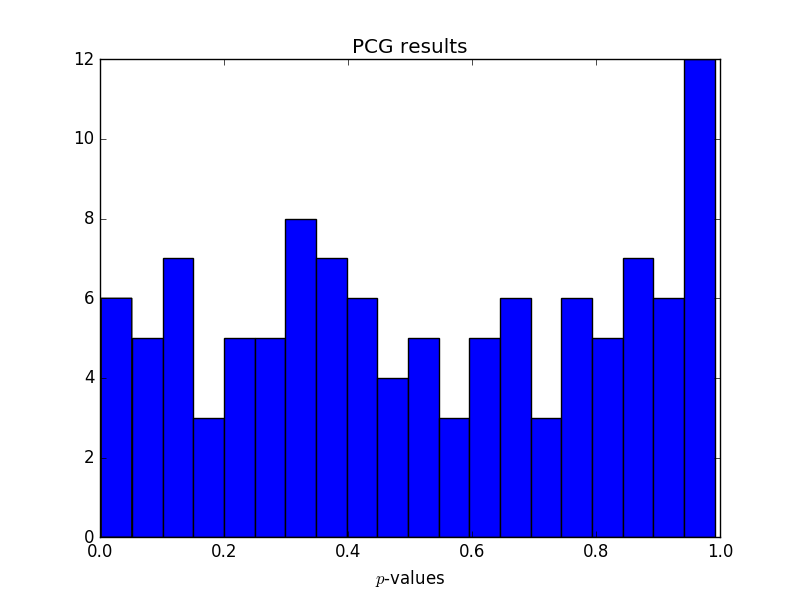
Neither test has too many small p-values, no more than we’d expect. This is normally what we’re concerned about. Too many small p-values would indicate that the generated samples are showing behavior that would be rare for truly random input.
But both sets of test results have a surprising number of large p-values. Not sure what to make of that. I suspect it says more about the DIEHARDER test suite than the random number generators being tested.
Update: I went back to look at some results from Mersenne Twister to see if this pattern of large p-values persists there. It does, and in fact the p-values are even more biased toward the high end for Mersenne Twister.
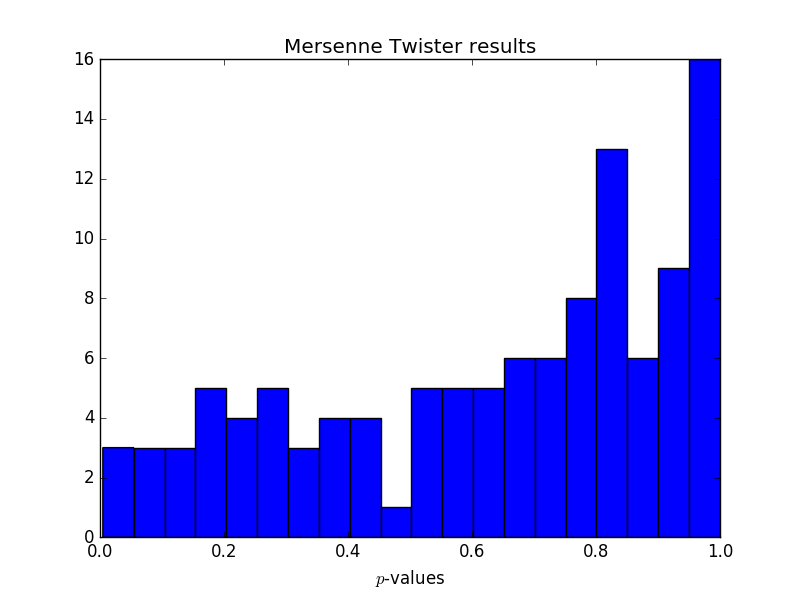
One thing I noticed is that the large p-values are disproportionately coming from some of the same tests each time. In particular, the repetitions of thests_serial test have an unexpectedly high number of large p-values for each generator.
If you’d like someone to run DIEHARDER or other RNG test suites, let’s talk. We have run these tests for other clients and we’d be glad to run them for you.
My experience has been that getting an excessive number of p-values from a hypothesis test is a sign that an independence assumption has failed somehow: for example, an error in the number of samples consistently produces plots like those above.
Lack of independence might explain everything. We’re not running one test on multiple independent data sets but multiple tests on a single data set. These tests might be independent in some conceptual sense, but not in a strict probabilistic sense.
I imagine the p-values are less correlated when testing better RNGs; a bad RNG would have small p-values on many tests. PCG may be the best of these RNGs — it outperforms MT in the tests in the author’s preprint, but it’s new and so hasn’t been subjected to as much scholarly scrutiny — and it has the most uniform distribution of p-values in the runs above.
In particular, if the generators are specifically designed to fool certain kinds of tests, you might expect high p-values for the tests that were deliberately spoofed. Nobody is randomly generating generators and publishing the ones that happen to pass a bunch of tests for statistical independence of output.
I think the previous comments are way off track (no offense). The high p-value simply suggests that the errors are closer to the ‘average expected error’, or perhaps 50th percentile is a better description. Some tests do not even ‘stress’ the generator, in the sense that the inherit structure is not well-measured by the test.
OK, John. I’m a bit piqued by your comment that you would not suggest Marsaglia’s MWC for integration by darts, (although you did follow up with the technique of importance sampling). So, you have to recommend a PRNG for a friend with a very fast computer, and he is going to be using it for lots of varied work, and speed neither first nor second priority. What generator would you recommend as the one you would trust as having the very highest quality, a nearly bullet-proof generator for the most teasingly subtle scenarios?