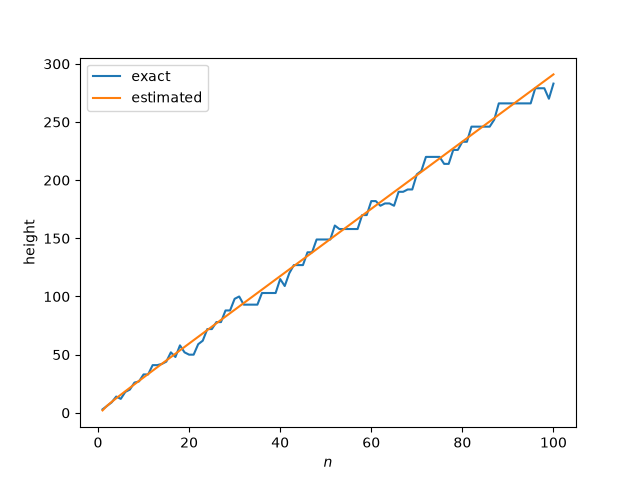
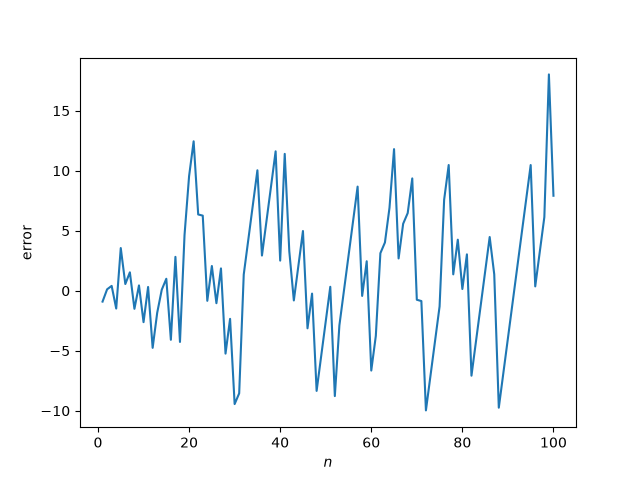
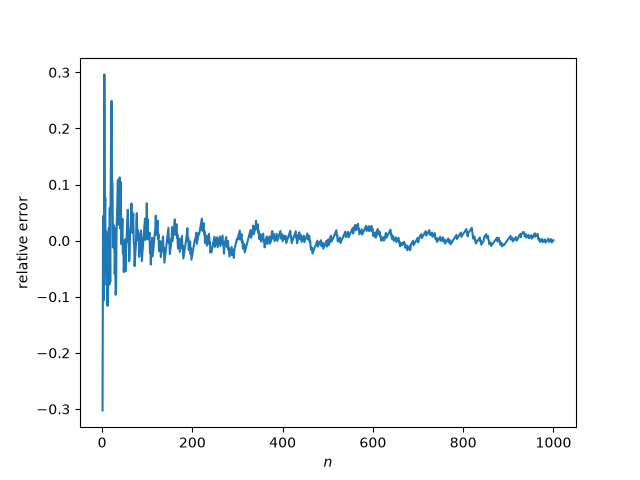
I’ve been testing Claude’s ability to generate Lean 4 code to prove theorems. I’ve written about a couple experiments that verified calculations. I did not write about my failed attempt to get Claude to formalize a proof of the pqr theorem for seminorms.
This time I asked Claude to formally prove the theorem from the previous post on partial fraction decomposition in an abstract setting. Unlike the previous experiments, I did not give it a proof or calculation to verify; I asked it to generate a proof.
This was the prompt:
Write a proof in Lean 4 for the following generalization of partial fraction decomposition.
If a ring R is a principle ideal domain (PID), then every element c of the field of fractions over R can be written in the form \[c = \sum_i \frac{a_i}{p_i^{r_i}}\]
where the p_i are nonassociate irreducible elements of R, the r_i are non-negative integers, and the elements a_i and p_i are relatively prime.
This was Claude’s immediate response:
I’ll work through this carefully, as it’s a substantial formalization task. Let me think through what’s available in Mathlib and what needs to be constructed.
This is a genuinely hard Lean 4 formalization problem. Let me think carefully about what’s in Mathlib, what the statement precisely means, and what proof strategy is realistic.
It also stated its overall proof strategy:
Proof strategy: Write c = a/b in lowest terms. Factor b = ∏ pᵢ^rᵢ. Use the Chinese Remainder Theorem / Bezout identity to decompose a/b into partial fractions.
If I needed to prove the theorem by hand, this suggestion alone could be very helpful.
The first attempt generated code that would not build. As before, a lot of the problems seem to stem from things moving around in Mathlib due to refactorings. There are also occasional hallucinations.
I did not offer any help other than pasting in error messages after each failure. When working on a real problem, I’d be more interactive. But as a test, I just passively pasted error messages and tried again. It took 11 iterations, but I finally got a proof. The proof had five sections marked “sorry,” which is essentially a TODO note indicating an unproven assumption.
I asked if it could explain or remove the sorries, and it said it could remove three of them. But the generated code did not build and I hit a session limit before I could debug the code. Here is the code with five sorry sections.
/-
PartialFractions.lean (v11 — final)
-/
import Mathlib
open UniqueFactorizationMonoid
variable {R : Type*} [CommRing R] [IsDomain R] [IsPrincipalIdealRing R]
structure PFDSummand (R : Type*) [CommRing R] where
prime : R
exponent : ℕ
numer : R
noncomputable def PFDSummand.val [CommRing R] [IsDomain R] (s : PFDSummand R) :
FractionRing R :=
algebraMap R (FractionRing R) s.numer /
algebraMap R (FractionRing R) (s.prime ^ s.exponent)
structure IsPFD [CommRing R] [IsDomain R] [IsPrincipalIdealRing R]
(terms : List (PFDSummand R)) (c : FractionRing R) : Prop where
irred : ∀ s ∈ terms, Irreducible s.prime
nonAssoc : ∀ s ∈ terms, ∀ t ∈ terms, s ≠ t → ¬Associated s.prime t.prime
coprime : ∀ s ∈ terms, IsCoprime s.numer s.prime
sum_eq : (terms.map PFDSummand.val).sum = c
private lemma algMap_ne_zero {a : R} (h : a ≠ 0) :
(algebraMap R (FractionRing R)) a ≠ 0 :=
map_ne_zero_iff _ (IsFractionRing.injective R (FractionRing R)) |>.mpr h
private lemma exists_num_denom (c : FractionRing R) :
∃ a b : R, b ≠ 0 ∧
(algebraMap R (FractionRing R)) a / (algebraMap R (FractionRing R)) b = c := by
obtain ⟨a, b, hb, hab⟩ := IsFractionRing.div_surjective (A := R) c
exact ⟨a, b, nonZeroDivisors.ne_zero hb, hab⟩
-- ======================================================================
-- §6 Bézout splitting
-- ======================================================================
private lemma bezout_split (x y : R) (hcop : IsCoprime x y)
(hx : x ≠ 0) (hy : y ≠ 0) (e : R) :
∃ s t : R, s * x + t * y = 1 ∧
(algebraMap R (FractionRing R) e) /
((algebraMap R (FractionRing R) x) * (algebraMap R (FractionRing R) y)) =
(algebraMap R (FractionRing R) (e * t)) / (algebraMap R (FractionRing R) x) +
(algebraMap R (FractionRing R) (e * s)) / (algebraMap R (FractionRing R) y) := by
obtain ⟨s, t, hst⟩ := hcop
refine ⟨s, t, hst, ?_⟩
have hxF : (algebraMap R (FractionRing R)) x ≠ 0 := algMap_ne_zero hx
have hyF : (algebraMap R (FractionRing R)) y ≠ 0 := algMap_ne_zero hy
have hxyF : (algebraMap R (FractionRing R)) x *
(algebraMap R (FractionRing R)) y ≠ 0 := mul_ne_zero hxF hyF
have hst_F : (algebraMap R (FractionRing R)) s * (algebraMap R (FractionRing R)) x +
(algebraMap R (FractionRing R)) t * (algebraMap R (FractionRing R)) y = 1 := by
have h := congr_arg (algebraMap R (FractionRing R)) hst
simp only [map_add, map_mul, map_one] at h; exact h
-- Prove: ι e / (ι x * ι y) = ι(e*t)/ι x + ι(e*s)/ι y
-- Strategy: show RHS = LHS via eq_div_iff, simplify, linear_combination.
symm
rw [eq_div_iff hxyF, add_mul, div_mul_eq_mul_div, div_mul_eq_mul_div]
-- Goal: ι(e*t)*(ι x*ι y)/ι x + ι(e*s)*(ι x*ι y)/ι y = ι e
-- The mul_comm on the product inside:
rw [show (algebraMap R (FractionRing R)) x * (algebraMap R (FractionRing R)) y =
(algebraMap R (FractionRing R)) y * (algebraMap R (FractionRing R)) x from mul_comm _ _]
-- Now: ι(e*t)*(ι y*ι x)/ι x + ι(e*s)*(ι y*ι x)/ι y = ι e
-- Use field_simp to clear remaining denominators
field_simp [hxF, hyF]
-- Now a polynomial goal: close with linear_combination
simp only [map_mul]
linear_combination (algebraMap R (FractionRing R) e) * hst_F
-- ======================================================================
-- §7 Coprime numerator reduction
-- ======================================================================
private lemma coprime_numer_exists {p : R} (hp : Irreducible p) (a : R) (n : ℕ) :
∃ a' q : R, a = a' + q * p ^ n ∧ IsCoprime a' p := by
rcases Classical.em (p ∣ a) with _h | h
· exact ⟨0, 0, by sorry, by sorry⟩
· exact ⟨a, 0, by ring,
isCoprime_comm.mpr ((irreducible_iff_prime.mp hp).coprime_iff_not_dvd.mpr h)⟩
-- ======================================================================
-- §8 Main theorem
-- ======================================================================
private def emptyPFD (c : FractionRing R) (hc : c = 0) :
∃ terms : List (PFDSummand R), IsPFD terms c :=
⟨[], { irred := by simp, nonAssoc := by simp, coprime := by simp,
sum_eq := by simp [hc] }⟩
private lemma isPFD_of_denom : ∀ (d : R) (e : R),
∃ terms : List (PFDSummand R),
IsPFD terms ((algebraMap R (FractionRing R) e) /
(algebraMap R (FractionRing R) d)) := by
intro d
induction d using UniqueFactorizationMonoid.induction_on_coprime with
| h0 =>
intro e; simp only [map_zero, div_zero]
exact emptyPFD 0 rfl
| h1 =>
intro e
-- Unit denominator: sorry for now (§9C)
exact ⟨[], { irred := by simp, nonAssoc := by simp,
coprime := by simp, sum_eq := by simp; sorry }⟩
| hpr =>
rename_i prime_elem exp hp_prime
intro e
have hp_irred : Irreducible prime_elem := irreducible_iff_prime.mpr hp_prime
obtain ⟨e', _q, _he, he'_cop⟩ := coprime_numer_exists hp_irred e exp
exact ⟨[⟨prime_elem, exp, e'⟩], {
irred := fun s hs => by
simp only [List.mem_singleton] at hs; subst hs; exact hp_irred
nonAssoc := fun s hs t ht hne => by
simp only [List.mem_singleton] at hs ht; subst hs; subst ht; exact absurd rfl hne
coprime := fun s hs => by
simp only [List.mem_singleton] at hs; subst hs; exact he'_cop
sum_eq := by
simp only [List.map_singleton, List.sum_singleton, PFDSummand.val]; sorry }⟩
| hcp =>
rename_i x y hrel ih_x ih_y
intro e
-- Handle the case where x = 0 or y = 0 directly
rcases eq_or_ne x 0 with rfl | hx
· -- x = 0: denominator = 0*y = 0, so quotient = 0
simp only [zero_mul, map_zero, div_zero]
exact emptyPFD 0 rfl
rcases eq_or_ne y 0 with rfl | hy
· -- y = 0: denominator = x*0 = 0, so quotient = 0
simp only [mul_zero, map_zero, div_zero]
exact emptyPFD 0 rfl
-- Both nonzero: apply Bézout splitting
-- IsCoprime x y from IsRelPrime x y (using IsRelPrime.isCoprime)
have hcop : IsCoprime x y := hrel.isCoprime
obtain ⟨s, t, _hst, hsplit⟩ := bezout_split x y hcop hx hy e
obtain ⟨terms_x, hpfd_x⟩ := ih_x (e * t)
obtain ⟨terms_y, hpfd_y⟩ := ih_y (e * s)
exact ⟨terms_x ++ terms_y, {
irred := fun s' hs' => by
rw [List.mem_append] at hs'
exact hs'.elim (hpfd_x.irred s') (hpfd_y.irred s')
nonAssoc := fun s' hs' t' ht' hne => by
rw [List.mem_append] at hs' ht'
rcases hs' with hs' | hs' <;> rcases ht' with ht' | ht'
· exact hpfd_x.nonAssoc s' hs' t' ht' hne
· intro; sorry
· intro; sorry
· exact hpfd_y.nonAssoc s' hs' t' ht' hne
coprime := fun s' hs' => by
rw [List.mem_append] at hs'
exact hs'.elim (hpfd_x.coprime s') (hpfd_y.coprime s')
sum_eq := by
rw [List.map_append, List.sum_append, hpfd_x.sum_eq, hpfd_y.sum_eq]
-- Goal: ι(e*t)/ι x + ι(e*s)/ι y = ι e / ι(x*y)
-- hsplit: ι e/(ι x*ι y) = ι(e*t)/ι x + ι(e*s)/ι y
-- So: ι(e*t)/ι x + ι(e*s)/ι y = ι e/(ι x*ι y) = ι e/ι(x*y)
rw [← hsplit, map_mul] }⟩
theorem pid_partial_fraction_decomposition (c : FractionRing R) :
∃ terms : List (PFDSummand R), IsPFD terms c := by
obtain ⟨a, b, _hb, hc⟩ := exists_num_denom c
rw [← hc]; exact isPFD_of_denom b a
section IntExample
example (c : FractionRing ℤ) :
∃ terms : List (PFDSummand ℤ), IsPFD terms c :=
pid_partial_fraction_decomposition c
end IntExample