Suppose you’re searching for medical diagnosis codes in the middle of free text. One way to go about this would be to search for each of the roughly 14,000 ICD-9 codes and each of the roughly 70,000 ICD-10 codes. A simpler approach would be to use regular expressions, though that may not be as precise.
In practice regular expressions may have some false positives or false negatives. The expressions given here have only false positives. That is, no valid ICD-9 or ICD-10 codes will go unmatched, but the regular expressions may match things that are not diagnosis codes. The latter is inevitable anyway since a string of characters could coincide with a diagnosis code but not be used as a diagnosis code. For example 1234 is a valid ICD-9 code, but 1234 in a document could refer to other things, such as a street address.
ICD-9 diagnosis code format
Most ICD-9 diagnosis codes are just numbers, but they may also start with E or V.
Numeric ICD-9 codes are at least three digits. Optionally there may be a decimal followed by one of two more digits.
An E code begins with E and three digits. These may be followed by a decimal and one more digit.
A V code begins with a V followed by two digits. These may be followed by a decimal and one or two more digits.
Sometimes the decimals are left out.
Here are regular expressions that summarize the discussion above.
N = "\d{3}\.?\d{0,2}"
E = "E\d{3}\.?\d?"
V = "V\d{2}\.?\d{0,2}"
icd9_regex = "|".join([N, E, V])
Usually E and V are capitalized, but they don’t have to be, so it would be best to do a case-insensitive match.
ICD-10 diagnosis code format
ICD-10 diagnosis codes always begin with a letter (except U) followed by a digit. The third character is usually a digit, but could be an A or B [1]. After the first three characters, there may be a decimal point, and up to three more alphanumeric characters. These alphanumeric characters are never U. Sometimes the decimal is left out.
So the following regular expression would match any ICD-10 diagnosis code.
[A-TV-Z][0-9][0-9AB]\.?[0-9A-TV-Z]{0,4}
As with ICD-9 codes, the letters are usually capitalized, but not always, so it’s best to do a case-insensitive search. In addition to the pattern above, “special codes” may begin with U.
Testing the regular expressions
As mentioned at the beginning, the regular expressions here may have false positives. However, they don’t let any valid codes slip by. I downloaded lists of ICD-9 and ICD-10 codes from the CDC and tested to make sure the regular expressions here matched every code.
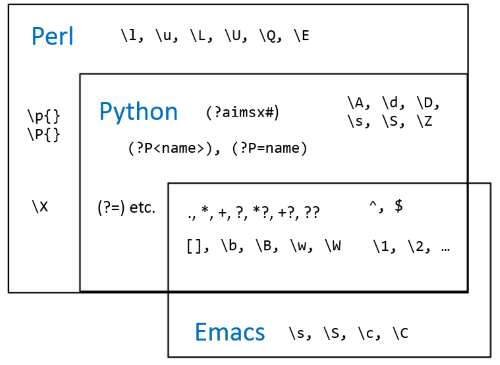
Regular expression features used
Character ranges are supported everywhere, such as [A-TV-Z] for the letters A through T and V through Z.
Not every regular expression implementation supports \d to represent a digit. In Emacs, for example, you would have to use[0-9] instead since it doesn’t support \d.
I’ve used \.? for an optional decimal point. (The . is a special character in regular expressions, so it needs to be escaped to represent a literal period.) Some people wold write [.]? instead on the grounds that it may be more readable. (Periods are not special characters in the context of a character classes.)
I’ve used {m} for a pattern that is repeated exactly m times, and {m,n} for a pattern that is repeated between m and n times. This is supported in Perl and Python, for example, but not everywhere. You could write \d\d\d instead of \d{3} and \d?\d? instead of \d{0,2}.
Related posts
[1] The only ICD-10 codes with a non-digit in the third position are those beginning with C4A, C7A, C7B, D3A, M1A, O9A, and Z3A.