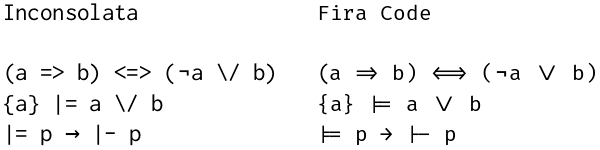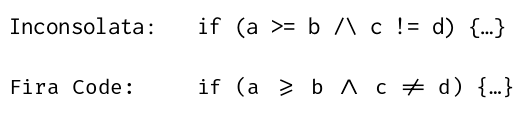Unicode 17.0 was released yesterday. According to the announcement
This version adds 4,803 new characters, including four new scripts, eight new emoji characters, as well as many other characters and symbols, bringing the total of encoded characters to 159,801.
My primary interest in Unicode is for symbols. Here are some of the new symbols I found interesting.
Currency
There’s a new symbol for the Saudi Riyal (SAR): U+20C1. This may be the most important symbol added in version 17. The rest are relatively arcane.

The riyal symbol looks like the Chinese symbol 北 (U+5317) which means “north.” However, according to the Saudi Central Bank the SAR symbol is based on a calligraphic form of the Arabic word riyal (ريال).
Note that the SAR symbol has parallel horizontal-ish lines, as many currency symbols do.
New math symbol
There was only one math-like symbol introduced in Unicode 17, and that is U+2B96, EQUALS SIGN WITH INFINITY ABOVE. I’ve never seen this symbol used anywhere, nor could I find any standard uses in a search.
![]()
I made the image above with \stackrel{\infty}{=} in LaTeX. If you flip the image upside down you get a symbol that was already in Unicode, U+2BF9, which is used in chess notation. I don’t know whether the new symbol is also used in chess notation.
I suppose the new symbol could be used to denote that two things are asymptotically equal. This would be more suggestive than the currently standard notation of using a tilde.
Asteroid symbols
Several asteroids already had Unicode symbols: Ceres, Pallas, Juno, Vesta, and Chiron correspond to U+26B3 through U+26B7. Also, Proserpina, Astraea, Hygiea, Pholus, and Nessus have Unicode symbols U+2BD8 through U+2BDC.
In Unicode 17.0, a new list of asteroids have symbols: Hebe, Iris, Flora, Metis, Parthenope, Victoria, Egeria, Irene, Eunomia, Psyche, Thetis, Melpomene, Fortuna, Proserpina, Bellona, Amphitrite, Leukothea. These correspond to U+1CEC0 through U+1CED0.
Four of these asteroids have alternate symbols add in the new version of Unicode: Vesta, Astraea, Hygiea, Parthenope have alternate forms in U+1F777 through U+1F77A. These alternate forms are listed under alchemical symbols.
Incidentally, not only a Pallas and Vesta the names of asteroids, they’re also the names of elliptic curves I wrote about recently.