Architect Peter Panholzer coined the term “squircle” in the summer of 1966 while working for Gerald Robinson. Robinson had seen a Scientific American article on the superellipse shape popularized by Piet Hein and suggested Panholzer use the shape in a project.
Piet Hein used the term superellipse for a compromise between an ellipse and a rectangle, and the term “supercircle” for the special case of axes of equal length. While Piet Hein popularized the superellipse shape, the discovery of the shape goes back to Gabriel Lamé in 1818.

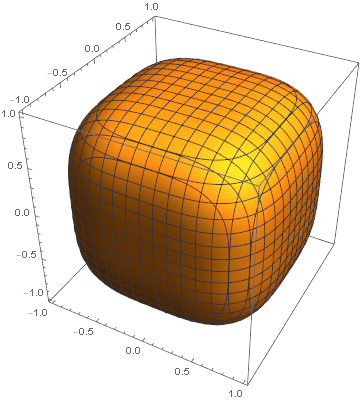
You can find more on the superellipse and squircle by following these links, but essentially the idea is to take the equation for an ellipse or circle and replace the exponent 2 with a larger exponent. The larger the exponent is, the closer the superellipse is to being a rectangle, and the closer the supercircle/squircle is to being a square.
Panholzer contacted me in response to my article on squircles. He gives several pieces of evidence to support his claim to have been the first to use the term. One is a letter from his employer at the time, Gerald Robinson. He also cites these links. [However, see Andrew Dalke’s comment below.]
Optimal exponent
As mentioned above, squircles and more generally superellipses, involve an exponent p. The case p = 2 gives a circle. As p goes to infinity, the squircle converges to a square. As p goes to 0, you get a star-shape as shown here. As noted in that same post, Apple uses p = 4 in some designs. The Sergels Torg fountain in Stockholm is a superellipse with p = 2.5. Gerald Robinson designed a parking garage using a superellipse with p = e = 2.71828.
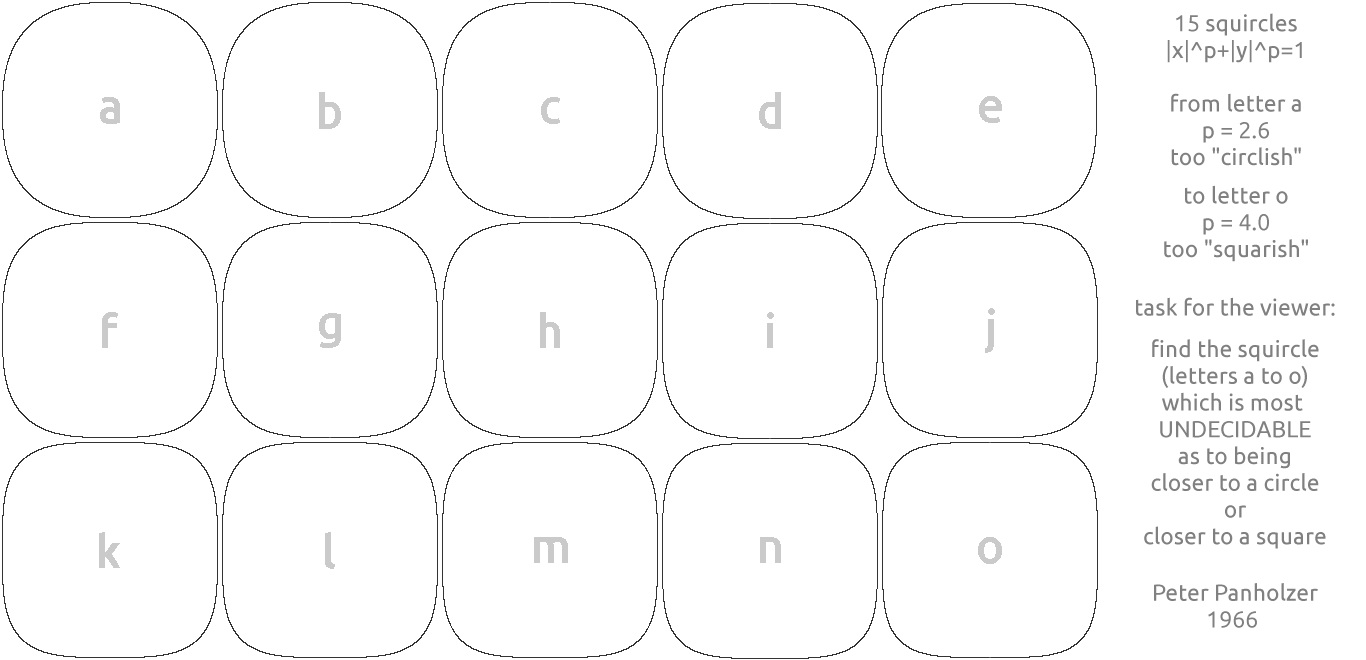
Panholzer experimented with various exponents [1] and decided that the optimal value of p would be the one for which the squircle has an area half way between the circle and corresponding square. This would create visual interest, leaving the viewer undecided whether the shape is closer to a circle or square.
The area of the portion of the unit circle contained in the first quadrant is π/4, and so we want to find the exponent p such that the area of the squircle in the first quadrant is (1 + π/4)/2. This means we need to solve

We can solve this numerically [2] to find p = 3.1620. It would be a nice coincidence if the solution were π, but it’s not quite.
Sometime around 1966 Panholzer had a conference table made in the shape of a squircle with this exponent.
Computing
I asked Panholzer how he created his squircles, and whether he had access to a computer in 1966. He did use a computer to find the optimal value of p; his brother in law, Hans Thurow, had access to a computer at McPhar Geophysics in Toronto. But he drew the plots by hand.
There was no plotter around at that time, but I used transparent vellum over graph paper and my architectural drawing skills with “French curves” to draw 15 squircles from p=2.6 (obviously “circlish”) to p=4.0 (obviously “squarish”).
More squircle posts
[1] The 15 plots mentioned in the quote at the end came first. A survey found that people preferred the curve corresponding to p around 3.1. Later the solution to the equation for the area to be half way between that of a circle and a square produced a similar value.
[2] Here are a couple lines of Mathematica code to find p.
f[p_] := Gamma[1 + 1/p]^2/Gamma[1 + 2/p]
FindRoot[f[p] - (1 + Pi/4)/2, {p, 4}]
The 4 in the final argument to FindRoot is just a suggested starting point for the search.







{kind=link}