Introduction
There’s an odd sort of partisan spirit to discussions of category theory. They often have the flavor of “Category theory is great!” or “Category theory is a horrible waste of time!” You don’t see this sort of partisanship around, say, probability. Probability theory is what it is, and if you need it, you use it. If you don’t need it, you don’t use it. I think of category theory in a similar way. It’s good for some things and not for others.
In this post I’ll look at just one little piece of category theory, the definition of products, and use it to give a flavor of category theory in general.
Initial objections
The first time I saw category theory’s definition of a product I thought it was a bizarre complication. “The product of A and B is an object P such that for any other object X …”
What is this X doing in our definition? It’s not our product, nor is it one of the things we’re taking the product of. And why introduce a diagram? Is the product of two mathematical objects a picture?! Why not come out and say what a product is rather than saying what it does? It’s just ordered pairs, right?
Category theory is all about how things behave rather than what they’re made of inside. So you could say that talking about pairs of elements violates the rules of the game. But that raises the question of why play this game at all. What do we get in return for placing such severe and unusual restrictions on ourselves?
The answer is that we get to see broader connections. When we focus on behavior rather than internal composition, we can see that two things behave the same even though they look different inside. Software developers should be familiar with this idea: depend on interface rather than implementation.
Definition
OK, so what is this mysterious definition of product? It’s a mouthful, but we’ll explain why it has to be what it is.
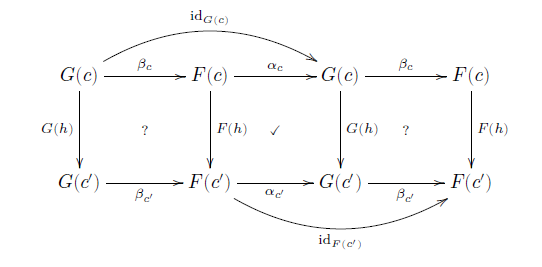
Given two objects A and B in some category, a product of A and B is an object P in that category and a pair of morphisms π1: P → A and π2: P → B such that for every object X with morphisms f1: X → A and f2: X → B, there exists a unique morphism f that makes the following diagram commute.
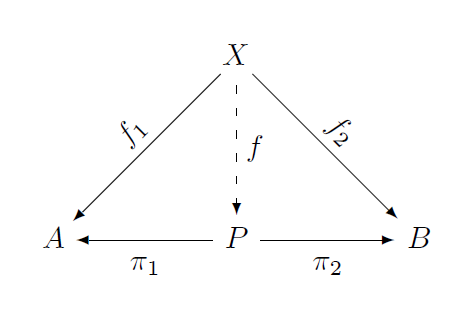
Whew! That’s a lot more work than saying a product is the set of ordered pairs (a, b) with a from A and b from B. And it’s not the first definition of product a student should see. However, there are three reasons why it’s worth introducing later:
- The ordered pair definition is not complete.
- The categorical definition is not as complex as it seems.
- The categorical definition makes new connections visible.
Why not ordered pairs
Saying “a product is just ordered pairs” isn’t enough. You have to say how the product relates to the things it’s a product of. In the case of a Cartesian product of sets, the projections are so obvious that it’s hard to realize they’re even there, but in general they need to be specified.
Another reason the ordered pair definition isn’t complete is that you need to say how the product is structured. If you’re taking the product of groups, for example, then you have to say how the group operation is defined on these ordered pairs. (There’s more than one way to do this. See here.) Or if you’re taking the product of two topological spaces, then you have to say what the topology is on this set whose points are the ordered pairs.
The categorical definition doesn’t tell you how to construct a product, but it tells you how to know when you’ve found something that works. That’s the trade-off: in order to have a theory that exposes wider connections, it can’t be tied to a specific example. Whether that’s an acceptable trade-off depends on your aim.
To reach further with our theory, we have to look at how things behave rather than how they are constructed. So how does a product behave? It lets you take components: here’s the first component, here’s the second. That’s about it. The categorical definition formalizes this in terms of projections, and it says that this is a universal property of products: anything else that acts like a product factors uniquely through the product.
In general you can’t just say products are ordered pairs. Sometimes products are not pairs, and sometimes pairs are not products. So the ordered pair definition doesn’t always apply. And when it does apply, it keeps us from seeing how products relate to coproducts, limits, and other operations.
When products are not pairs
Here’s an example of a product that’s not a pair. A partially ordered set can be viewed as a category. The elements of the set are the objects of the category, and there is an there is a morphism from a to b if a ≤ b. In that case the product of a and b is their minimum a ∧ b.
When pairs are not products
Here’s an example of a pair that’s not a product. The category of fields does not generally have products. You can form ordered pairs of elements from two fields, but you can’t always define any operation on these pairs that will turn them into a field.
For example, the number of elements in a finite field must be a power of a prime. If you take a field of order 5 and a field of order 7, there are 35 ordered pairs of elements, but there is no field of order 35.
But is it worth it?
The categorical definition of products is difficult to understand. It’s analogous to the δ-ε definition of limits: not the first thing you think of, but the rigorous definition that will generalize well into new situations.
Abstraction should follow experience, not precede it. You need to have multiple examples of products in you mind before you see any advantage to abstracting the idea of a product.
So what does the abstraction buy you? Maybe nothing! It depends on what you’re after. One thing it might do for you is help you to be more consistent. Programming language designers, for example, use category theory to make languages more consistent and easier to think about. A language might want to handle various kinds of products uniformly, even when the products look very different at first. In addition to consistently implementing what they should, category theory might guide designers to not implement what they shouldn’t. For example, above we said that it doesn’t make sense in general to take the product of two fields.
Category theory also suggests new questions. For example, duality is pervasive throughout category theory. For every concept, there’s a co-concept. So once you identify a product in some context, it’s natural to ask what coproducts are, and these tend to be less obvious than products. And going back to consistency, category theory might guide you to handle dual concepts in a dual manner.
More category theory posts