The average of two numbers, a and b, can be written as the average of x over the interval [a, b]. This is easily verified as follows.

The average is the arithmetic mean. We can represent other means as above if we generalize the pattern to be
![\varphi^{-1}\left(\,\text{average of } \varphi(x) \text{ over } [a, b] \,\right )](https://www.johndcook.com/integral_mean3.svg)
For the arithmetic mean, φ(x) = x.
Logarithmic mean
If we set φ(x) = 1/x we have

and the last expression is known as the logarithmic mean of a and b.
Geometric mean
If we set φ(x) = 1/x² we have

which gives the geometric mean of a and b.
Identric mean
In light of the means above, it’s reasonable ask what happens if we set φ(x) = log x. When we do we get a more arcane mean, known as the identric mean.
The integral representation of the identric mean seems natural, but when we compute the integral we get something that looks arbitrary.

The initial expression looks like something that might come up in application. The final expression looks artificial.
Because the latter is more compact, you’re likely to see the identric mean defined by this expression, then later you might see the integral representation. This is unfortunate since the integral representation makes more sense.
Order of means
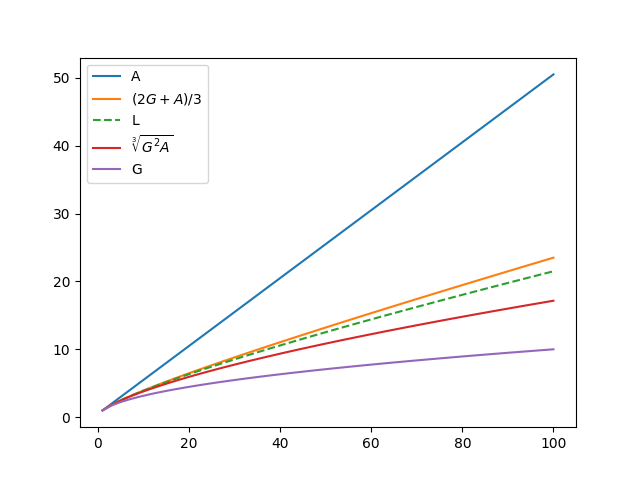
It is well known that the geometric mean is no greater than the arithmetic mean. The logarithmic and identric means squeeze in between the geometric and arithmetic means.
If we denote the geometric, logarithmic, identric, and arithmetic means of a and b by G, L, I, and A respectively,

Related posts