I was reading an article this morning that mentioned a stylometric analysis of a controversial paragraph written by Roman historian Flavius Josephus. I’ve written several posts that could be called stylometry or adjacent, but I haven’t used that word. Here are some posts that touch on the statistical analysis of a text or of an author.
NLP
More on seed phrase words
Last week I wrote about how the English seed phrase words for crypto wallets, proposed in BIP39, are not ideal for memorization. This post gives a few more brief thoughts based on these words.
Prefix uniqueness
The BIP39 words have a nice property that I didn’t mention: the words are uniquely determined by their first four letters. This means, for example, that you could type in a seed phrase on a phone by typing the first four letters of each word and a wallet interface could fill in the rest of each word.
Incidentally, although the BIP39 words are unique in how they begin, they are not unique in how they end. For example, cross and across are both on the list.
Creating a list
I wondered how hard it would be to come up with a list of 2048 common words that are unique in their first four letters. So I started with Google’s list of 10,000 most common words.
I removed one- and two-letter words, and NSFW words, to try to create a list similar to the BIP39 words. That resulted in a list of 4228 words. You could delete over half of these words and have a list of 2048 words uniquely determined by their first four letters.
Comparing lists
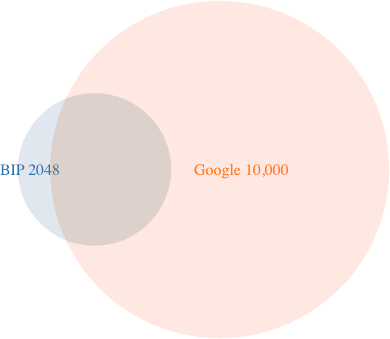
I was curious how many of the BIP39 list of 2048 words were contained in Google’s list of 10,000 most common words. The answer is 1666, or about 81%. (Incidentally, I used comm to answer this.)
Vocabulary estimation and overlap
Here’s something else I was curious about. The average adult has an active vocabulary of between 20,000 and 35,000 words. So it seems reasonable that a typical adult would know nearly all the words on Google’s top 10,000 list. (Not entirely all. For example, I noticed one word on Google’s list that I hadn’t seen before.)
Now suppose you had a list of the 20,000 most common words and a person with a vocabulary of 20,000 words. How many words on the list is this person likely to know? Surely not all. We don’t acquire our vocabulary by starting at the top of a list of words, ordered by frequency, and working our way down. We learn words somewhat at random according to our circumstances. We’re more likely to know the most common words, but it’s not certain. So how would you model that?
It’s interesting to think how you would estimate someone’s vocabulary in the first place. You can’t give someone a quiz with every English word and ask them to check off the words they know, and estimation complicated by the fact that word frequencies are far from uniform. Maybe the literature on vocabulary estimation would answer the questions in the previous paragraph.
Related posts
Analyzing the Federalist Papers
The Federalist Papers, a collection of 85 essays published anonymously between 1787 and 1788, were one of the first subjects for natural language processing aided by a computer. Because the papers were anonymous, people were naturally curious who wrote each of the essays. Early on it was determined that the authors were Alexander Hamilton, James Madison, and John Jay, but the authorship of individual essays wasn’t known.
In 1944, Douglass Adair conjectured the authorship of each essay, and twenty years later Frederick Mosteller and David Wallace confirmed Adair’s conclusions by Bayesian analysis. Mosteller and Wallace used a computer to carry out their statistical calculations, but they did not have an electronic version of the text.
They physically chopped a printed copy of the text into individual words and counted them. Mosteller recounted in his autobiography that until working on The Federalist Papers, he had underestimated how hard it was to count a large number things, especially little pieces of paper that could be scattered by a draft.
I’m not familiar with how Mosteller and Wallace did their analysis, but I presume they formed a prior distribution on the frequency of various words in writings known to be by Hamilton, Madison, and Jay, then computed the posterior probability of authorship by each author for each essay.
The authorship of the papers was summarized in the song “Non-Stop” from the musical Hamilton:
The plan was to write a total of twenty-five essays, the work divided evenly among the three men. In the end, they wrote eighty-five essays in the span of six months. John Jay got sick after writing five. James Madison wrote twenty-nine. Hamilton wrote the other fifty-one!
Yesterday I wrote about the TF-IDF statistic for the importance of words in a corpus of documents. In that post I used the books of the Bible as my corpus. Today I wanted to reuse the code I wrote for that post by applying it to The Federalist Papers.
Federalist No. 10 is the best known essay in the collection. Here are the words with the highest TF-IDF scores from that essay.
faction: 0.0084
majority: 0.0047
democracy: 0.0044
controlling: 0.0044
parties: 0.0039
republic: 0.0036
cure: 0.0035
factious: 0.0035
property: 0.0033
faculties: 0.0033
I skimmed a list of the most important words in the essays by Madison and Hamilton and noticed that Madison’s list had several words from classic literature: Achaeans, Athens, Draco, Lycurgus, Sparta, etc. There were a only couple classical references in Hamilton’s top words: Lysander and Pericles. I noticed “debt” was important to Hamilton.
You can find the list of top 10 words in each essay here.
Using TF-IDF to pick out important words
TF-IDF (Term Frequency-Inverse Document Frequency) is commonly used in natural language processing to extract important words. The idea behind the statistic is that a word is important if it occurs frequently in a particular document but not frequently in the corpus of documents the document came from.
The term-frequency (TF) of a word in a document is the probability of selecting that word at random from the document, i.e. the number of times the word appears in the document divided by the total number of words in the document.
Inverse document frequency (IDF) is not quite what the name implies. You might reasonably assume that inverse document frequency is the inverse (i.e. reciprocal) of document frequency, where document frequency is the proportion of documents containing the word. Or in other words, the reciprocal of the probability of selecting a document at random containing the word. That’s almost right, except you take the logarithm.
TF-IDF for a word and a document is the product of TF and IDF for that word and document. You could say
TF-IDF = TF * IDF
where the “-” on the left side is a hyphen, not a minus sign.
To try this out, let’s look at the King James Bible. The text is readily available, for example from Project Gutenberg, and it divides into 66 documents (books).
Note that if a word appears in every document, in our case every book of the Bible, then IDF = log(1) = 0. This means that common words like “the” and “and” that appear in every book get a zero score.
Here are the most important words in Genesis, as measured by TF-IDF.
laban: 0.0044
abram: 0.0040
joseph: 0.0037
jacob: 0.0034
esau: 0.0032
rachel: 0.0031
said: 0.0031
pharaoh: 0.0030
rebekah: 0.0029
duke: 0.0028
It’s surprising that Laban comes out on top. Surely Joseph is more important than Laban, for example. Joseph appears more often in Genesis than does Laban, and so has a higher TF score. But Laban only appears in two books, whereas Joseph appears in 23 books, and so Laban has a higher IDF score.
Note that TF-IDF only looks at sequences of letters. It cannot distinguish, for example, the person named Laban in Genesis from the location named Laban in Deuteronomy.
Another oddity above is the frequency of “duke.” In the language of the KJV, a duke was the head of a clan. It wasn’t a title of nobility as it is in contemporary English.
The most important words in Revelation are what you might expect.
angel: 0.0043
lamb: 0.0034
beast: 0.0033
throne: 0.0028
seven: 0.0028
dragon: 0.0025
angels: 0.0025
bottomless: 0.0024
overcometh: 0.0023
churches: 0.0022
You can find the top 10 words in each book here.
Related posts
Spreading out words in space
A common technique for memorizing numbers is to associate numbers with words. The Major mnemonic system does this by associating consonant sounds with each digit. You form words by inserting vowels as you please.
There are many possible encodings of numbers, but sometimes you want to pick a canonical word for each number, what’s commonly called a peg. Choosing pegs for the numbers 1 through 10, or even 1 through 100, is not difficult. Choosing pegs for a larger set of numbers becomes difficult for a couple reasons. First, it’s hard to think of words to fit some three-digit numbers. Second, you want your pegs to be dissimilar in order to avoid confusion.
Say for example you’ve chosen “syrup” for 049 and you need a peg for 350. You could use “molasses,” but that’s conceptually similar to “syrup.” If you use “Miles Davis” for 350 then there’s no confusion [1].
You could quantify how similar words are using cosine similarity between word embeddings. A vector embedding associates a high-dimensional vector with each word in such a way that the geometry corresponds roughly with meaning. The famous example is that you might have, at least approximately,
queen = king − man + woman.
This gives you a way to define angles between words that ideally corresponds to conceptual similarity. Similar words would have a small angle between their vectors, while dissimilar words would have larger angles.
If you wanted to write a program to discover pegs for you, say using some corpus like ARPABet, you could have it choose alternatives that spread the words out conceptually. It’s debatable how practical this is, but it’s interesting nonetheless.
The angles you get would depend on the embedding you use. Here I’ll use the gensim code I used earlier in this post.
The angle between “syrup” and “molasses” is 69° but the angle between “syrup” and “miles” is 84°. The former is larger than I would have expected, but still significantly smaller than the latter. If you were using cosine similarity to suggest mnemonic pegs, hopefully the results would be directionally useful, choosing alternatives that minimize conceptual overlap.
As I said earlier, it’s debatable how useful this is. Mnemonics are very personal. A musician might be fine with using “trumpet” for 143 and “flugelhorn” for 857 because in his mind they’re completely different instruments, but someone else might think they’re too similar. And you might not want to use “Miles Davis” and “trumpet” as separate pegs, even though software will tell you that “miles” and “trumpet” are nearly orthogonal.
Related posts
[1] Here we’re following the convention that only the first three consonants in a word count. This makes it easier to think of pegs.
Using WordNet to create a PAO system
NLP software infers parts of speech by context. For example, the SpaCy NLP software can determine the parts of speech in the poem Jabberwocky even though the words are nonsense. More on this here.
If you want to tell the parts of speech for isolated words, maybe software like SpaCy isn’t the right tool. You might use lists of nouns, verbs, etc. This is what I’ll do in this post using the WordNet corpus. I’d like to show how you could use WordNet to create a mnemonic system.
PAO (person-action-object)
One way that people memorize six-digit numbers, or memorize longer numbers six digits at a time, is the PAO (person-action-object) system. They memorize a list of 100 people, 100 actions, and 100 direct objects. The first two digits of a six-digit number are encoded as a person, the next two digits as an action, and the last two digits as an object. For example, “Einstein dances with a broom” might encode 201294 if 20 is associated with Einstein, 12 with dance, and 94 with broom.
These mappings could be completely arbitrary, but you could memorize them faster if there were some patterns to the mappings, such as using the Major mnemonic system.
I’ve written before about how to use the CMU Pronouncing Dictionary to create a list of words along with the numbers they correspond to in the Major system. This post will show how to pull out the nouns and verbs from this list. The nouns are potential objects and the verbs are potential actions. I may deal with persons in another post.
Noun and verb lists in WordNet
The WordNet data contains a file index.noun with nouns and other information. We want to discard the first 29 lines of preamble and extract the nouns in the first column of the file. We can do this with the following one-liner.
tail -n +30 index.noun | cut -d' ' -f1 > nouns.txt
Likewise we can extract a list of verbs with the following
tail -n +30 index.verb | cut -d' ' -f1 > verbs.txt
There is some overlap between the two lists since some words can be nouns or verbs depending on context. For example, running
grep '^read$' nouns.txt
and
grep '^read$' verbs.txt
shows that “read” is in both lists. (The regex above anchors the beginning of the match with ^ and the end with $ so we don’t get unwanted matches like “treadmill” and “readjust.”)
Sorting CMU dictionary by part of speech
The following Python code will parse the file cmu_major.txt from here to pull out a list of nouns and a list of verbs, along with their Major system encodings.
with open("nouns.txt") as f:
nouns = set()
for line in f.readlines():
nouns.add(line.strip())
with open("verbs.txt") as f:
verbs = set()
for line in f.readlines():
verbs.add(line.strip())
cmunouns = open("cmu_nouns.txt", "w")
cmuverbs = open("cmu_verbs.txt", "w")
with open("cmu_major.txt") as f:
for line in f.readlines():
w = line.split()[0].lower()
if w in nouns:
cmunouns.write(line)
if w in verbs:
cmuverbs.write(line)
You can download the output if you’d like: cmu_nouns.txt, cmu_verbs.txt.
Going back to the example of 201294, the file cmu_verbs.txt contains 82 words that correspond to numbers starting with 12. And the file cmu_nouns.txt contains 1,057 words that correspond to numbers starting with 94.
Choosing verbs is the hard part. Although there are verbs for every number 00 through 99, many of these would not be good choices. You want active verbs that can be combined with any subject and object.
My impression is that most people who use the PAO system—I do not—pick their names, verbs, and objects without regard to the Major system, and I could understand why: your choices are sometimes limited if you want to be compatible with the Major system. You might compromise and use Major-compatible pegs when possible and make exceptions as needed.
Cosine similarity does not satisfy the triangle inequality
The previous post looked at cosine similarity for embeddings of words in vector spaces. Word embeddings like word2vec map words into high-dimensional vector spaces in such a way that related words correspond to vectors that are roughly parallel. Ideally the more similar the words, the smaller the angle between their corresponding vectors.
The cosine similarity of vectors x and y is given by
![]()
If the vectors are normalized to have length 1 (which word embeddings are typically not) then cosine similarity is just dot product. Vectors are similar when their cosine similarity is near 1 and dissimilar when their cosine similarity is near 0.
If x is similar to y and y is similar to z, is x similar to z? We could quantify this as follows.
Let cossim(x, y) be the cosine similarity between x and y.
If cossim(x, y)= 1 − ε1, and cossim(y, z) =1 − ε2, is cossim(x, z) at least 1 − ε1 − ε2? In other words, does the complement of cosine similarity satisfy the triangle inequality?
Counterexample
The answer is no. I wrote a script to search for a counterexample by generating random points on a sphere. Here’s one of the examples it came up with.
x = [−0.9289 −0.0013 0.3704]
y = [−0.8257 0.3963 0.4015]
z = [−0.6977 0.7163 −0.0091]
Let d1 = 1 − cossim(x, y), d2 = 1 − cossim(y, z), and d3 be 1 − cossim(x, z).
Then d1 = 0.0849, d2 = 0.1437, and d3 = 0.3562 and so d3 > d1 + d2.
Triangle inequality
The triangle inequality does hold if we work with θs rather than their cosines. The angle θ between two vectors is the distance between these two vectors interpreted as points on a sphere and the triangle inequality does hold on the sphere.
Approximate triangle inequality
If the cosine similarity between x and y is close to 1, and the cosine similarity between y and z is close to 1, then the cosine similarity between x and z is close to one, though the triangle inequality may not hold. I wrote about this before in the post Nearly parallel is nearly transitive.
I wrote in that post that the law of cosines for spherical trigonometry says
cos c = cos a cos b + sin a sin b cos γ
where γ is the angle between the arcs a and b. If cos a = 1 − ε1, and cos b = 1 − ε2, then
cos a cos b = (1 − ε1)(1 − ε2) = 1 − ε1 − ε2 + ε1 ε2
If ε1 and ε2 are small, then their product is an order of magnitude smaller. Also, the term
sin a sin b cos γ
is of the same order of magnitude. So if 1 − cossim(x, y) = ε1 and 1 − cossim(y, z) = ε2 then
1 − cossim(x, z) = ε1 + ε1 + O(ε1 ε2)
Is the triangle inequality desirable?
Cosine similarity does not satisfy the triangle inequality, but do we want a measure of similarity between words to satisfy the triangle inequality? You could argue that semantic similarity isn’t transitive. For example, lion is similar to king in that a lion is a symbol for a king. And lion is similar to house cat in that both are cats. But king and house cat are not similar. So the fact that cosine similarity does not satisfy the triangle inequality might be a feature rather than a bug.
Related posts
Angles between words
Natural language processing represents words as high-dimensional vectors, on the order of 100 dimensions. For example, the glove-wiki-gigaword-50 set of word vectors contains 50-dimensional vectors, and the the glove-wiki-gigaword-200 set of word vectors contains 200-dimensional vectors.
The intent is to represent words in such a way that the angle between vectors is related to similarity between words. Closely related words would be represented by vectors that are close to parallel. On the other hand, words that are unrelated should have large angles between them. The metaphor of two independent things being orthogonal holds almost literally as we’ll illustrate below.
Cosine similarity
For vectors x and y in two dimensions,
![]()
where θ is the angle between the vectors. In higher dimensions, this relation defines the angle θ in terms of the dot product and norms:
![]()
The right-hand side of this equation is the cosine similarity of x and y. NLP usually speaks of cosine similarity rather than θ, but you could always take the inverse cosine of cosine similarity to compute θ. Note that cos(0) = 1, so small angles correspond to large cosines.
Examples
For our examples we’ll use gensim with word vectors from the glove-twitter-200 model. As the name implies, this data set maps words to 200-dimensional vectors.
Note that word embeddings differ in the data they were trained on and the algorithm used to produce the vectors. The examples below could be very different using a different source of word vectors.
First some setup code.
import numpy as np
import gensim.downloader as api
word_vectors = api.load("glove-twitter-200")
def norm(word):
v = word_vectors[word]
return np.dot(v, v)**0.5
def cosinesim(word0, word1):
v = word_vectors[word0]
w = word_vectors[word1]
return np.dot(v, w)/(norm(word0)*norm(word1))
Using this mode, the cosine similarity between “dog” and “cat” is 0.832, which corresponds to about a 34° angle. The cosine similarity between “dog” and “wrench” is 0.145, which corresponds to an angle of 82°. A dog is more like a cat than like a wrench.
The similarity between “dog” and “leash” is 0.487, not because a dog is like a leash, but because the word “leash” is often used in the same context as the word “dog.” The similarity between “cat” and “leash” is only 0.328 because people speaking of leashes are more likely to also be speaking about a dog than a cat.
The cosine similarity between “uranium” and “walnut” is only 0.0054, corresponding to an angle of 89.7°. The vectors associated with the two words are very nearly orthogonal because the words are orthogonal in the metaphorical sense.
Note that opposites are somewhat similar. Uranium is not the opposite of walnut because things have to have something in common to be opposites. The cosine similarity of “expensive” and “cheap” is 0.706. Both words are adjectives describing prices and so in some sense they’re similar, though they have opposite valence. “Expensive” has more in common with “cheap” than with “pumpkin” (similarity 0.192).
The similarity between “admiral” and “general” is 0.305, maybe less than you’d expect. But the word “general” is kinda general: it can be used in more contexts than military office. If you add the vectors for “army” and “general”, you get a vector that has cosine similarity 0.410 with “admiral.”
Related posts
Sort and remove duplicates
A common idiom in command line processing of text files is
... | sort | uniq | ...
Some process produces lines of text. You want to pipe that text through sort to sort the lines in alphabetical order, then pass it to uniq to filter out all but the unique lines. The uniq utility only removes adjacent duplicates, and so it will not remove all duplicates unless the input is sorted. (At least the duplicate lines need to be grouped together; the groups need not be in any particular order.)
When given the -u flag, sort will sort and remove duplicates. This says the idiom above could be shortened to
... | sort -u | ...
Aside from saving a few keystrokes, is there any advantage to the latter? There could be, depending on how sort -u is implemented. If internally it simply sorts its input and then removes duplicates, then there is no advantage. But if the code simultaneously sorts and removes duplicates, it could save memory and time, depending on the input. If the code discarded duplicates as they were encountered, the code would need working memory proportional to the amount of unique input rather than the total amount of input.
I had a project recently that makes a good test case for this. The Gutenberg text corpus contains a list of words for 55,000 different sources, each in a separate text file. There are a lot of files, and there is a lot of redundancy between files. The combined file is 3.4 GB.
Running sort | uniq on the combined file took 610 seconds.
Running sort -u on the file took 394 seconds.
So in this example, sort -u not only saved a few keystrokes, it took about 35% off the time.
I expected it would save even more time. Maybe a custom program optimized for large files with a lot of redundancy could be even faster.
Update: awk
Bob Lyon’s comment made me think about using awk without concatenating the files together. Each of the 55,000 text files contains a word and a count. I didn’t concatenate the files per se but piped each through cut -f 1 to select the first column.
Using awk I created an associative array (a hash table, but awk calls them associative arrays) for each word, then printed out the keys of the array.
awk '{count[$1]++};
END {for (key in count) {print key}}' |
sort > out
This ran in 254 seconds, 58% faster than sort | uniq and 36% faster than sort -u.
There is a lot of redundancy between the files—the list of unique words is 320 times smaller than the union of all the input files—and the awk script takes advantage of this by maintaining an array roughly the size of the output rather than the size of the input.
Tim Chase suggested a more elegant solution:
awk '!count[$1]++ {print $1}' *.txt | sort > out
It seems this should be more efficient as well since awk only goes through the data once, immediately printing new values as they are encountered. However, it actually took slightly longer, 263 seconds.
ARPAbet and the Major mnemonic system

ARPAbet is a phonetic spelling system developed by— you guessed it—ARPA, before it became DARPA.
The ARPAbet system is less expressive than IPA, but much easier for English speakers to understand. Every sound is encoded as one or two English letters. So, for example, the sound denoted ʒ in IPA is ZH in ARPAbet.
In ARPAbet notation, the Major mnemonic system can be summarized as follows:
0: S or Z
1: D, DH, T, or DH
2: N or NG
3: M
4: R
5: L
6: CH, JH, SH, or ZH
7: G or K
8: F or V
9: P or B
Numbers are encoded using the consonant sounds above; the system is based on sounds and not on spelling. You can insert any vowels or semivowels (e.g. w or y) you like. For example, you could encode 648 as “giraffe” or 85 as “waffle.”
The CMU Pronouncing Dictionary lists 134,373 words along with their ARPAbet pronunciation. The Python code below will read in the pronouncing dictionary and produce a Major mnemonic dictionary. The resulting file is available here as a zip compressed text file.
To find a word that encodes a number, search the code output for that number. For example,
grep ' 648' cmu_major.txt
will find words whose Major encoding begins with 648, and
grep ' 648$' cmu_major.txt
fill find words whose Major encoding is exactly 648.
From this we learn that “sheriff” is another possible encoding for 648.
Filling in the gaps
Suppose you’re looking for encodings for all three digit numbers, 000 through 999. This can be hard to do. A common compromise is to only regard up to the first three consonants in a word. For example, you might use “ladybug” to encode 519, ignoring the final G sound on the end.
The tradeoff is that if you adopt this rule then you can’t use “ladybug” to encode 5197. But finding single words that encode 4-digit numbers can be challenging if not impossible, so you may just forego the possibility. (I quantify this here.) This is why in the example above I show both searching for numbers that begin with 648 and numbers that are exactly 648.
Despite the large size of the CMU dictionary, it does not contain words that map to numbers beginning with 42 three-digit numbers. I can offer suggestions for these numbers, but it’s hard to use anyone else’s mnemonics. You may have to make up your own, using, for example, names of people you know personally or brand names you’re familiar with etc.
Python code
# NB: File encoding is Latin-1, not UTF-8.
with open("cmudict-0.7b", "r", encoding="latin-1") as f:
lines = f.readlines()
for line in lines:
line.replace('0','') # remove stress notation
line.replace('1','')
line.replace('2','')
pieces = line.split()
numstr = ""
for p in pieces[1:]:
match p:
case "S" | "Z":
numstr += "0"
case "D" | "DH" | "T" | "DH":
numstr += "1"
case "N" | "NG":
numstr += "2"
case "M":
numstr += "3"
case "R":
numstr += "4"
case "L":
numstr += "5"
case "CH" | "JH" | "SH" | "ZH":
numstr += "6"
case "G" | "K":
numstr += "7"
case "F" | "V":
numstr += "8"
case "P" | "B":
numstr += "9"
print(pieces[0], numstr)