The previous post looked at cosine similarity for embeddings of words in vector spaces. Word embeddings like word2vec map words into high-dimensional vector spaces in such a way that related words correspond to vectors that are roughly parallel. Ideally the more similar the words, the smaller the angle between their corresponding vectors.
The cosine similarity of vectors x and y is given by
![]()
If the vectors are normalized to have length 1 (which word embeddings are typically not) then cosine similarity is just dot product. Vectors are similar when their cosine similarity is near 1 and dissimilar when their cosine similarity is near 0.
If x is similar to y and y is similar to z, is x similar to z? We could quantify this as follows.
Let cossim(x, y) be the cosine similarity between x and y.
If cossim(x, y)= 1 − ε1, and cossim(y, z) =1 − ε2, is cossim(x, z) at least 1 − ε1 − ε2? In other words, does the complement of cosine similarity satisfy the triangle inequality?
Counterexample
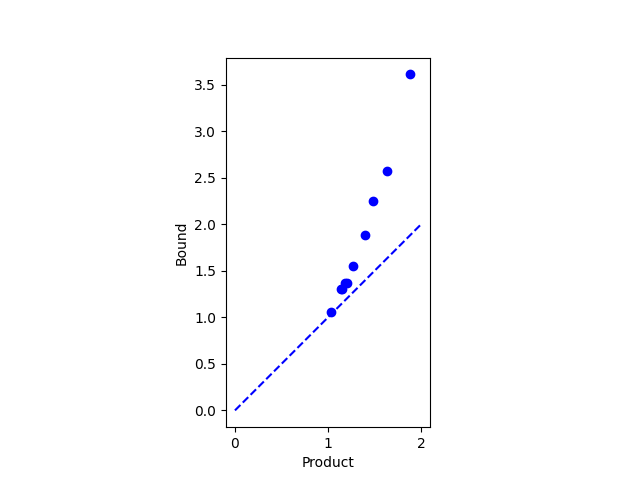
The answer is no. I wrote a script to search for a counterexample by generating random points on a sphere. Here’s one of the examples it came up with.
x = [−0.9289 −0.0013 0.3704]
y = [−0.8257 0.3963 0.4015]
z = [−0.6977 0.7163 −0.0091]
Let d1 = 1 − cossim(x, y), d2 = 1 − cossim(y, z), and d3 be 1 − cossim(x, z).
Then d1 = 0.0849, d2 = 0.1437, and d3 = 0.3562 and so d3 > d1 + d2.
Triangle inequality
The triangle inequality does hold if we work with θs rather than their cosines. The angle θ between two vectors is the distance between these two vectors interpreted as points on a sphere and the triangle inequality does hold on the sphere.
Approximate triangle inequality
If the cosine similarity between x and y is close to 1, and the cosine similarity between y and z is close to 1, then the cosine similarity between x and z is close to one, though the triangle inequality may not hold. I wrote about this before in the post Nearly parallel is nearly transitive.
I wrote in that post that the law of cosines for spherical trigonometry says
cos c = cos a cos b + sin a sin b cos γ
where γ is the angle between the arcs a and b. If cos a = 1 − ε1, and cos b = 1 − ε2, then
cos a cos b = (1 − ε1)(1 − ε2) = 1 − ε1 − ε2 + ε1 ε2
If ε1 and ε2 are small, then their product is an order of magnitude smaller. Also, the term
sin a sin b cos γ
is of the same order of magnitude. So if 1 − cossim(x, y) = ε1 and 1 − cossim(y, z) = ε2 then
1 − cossim(x, z) = ε1 + ε1 + O(ε1 ε2)
Is the triangle inequality desirable?
Cosine similarity does not satisfy the triangle inequality, but do we want a measure of similarity between words to satisfy the triangle inequality? You could argue that semantic similarity isn’t transitive. For example, lion is similar to king in that a lion is a symbol for a king. And lion is similar to house cat in that both are cats. But king and house cat are not similar. So the fact that cosine similarity does not satisfy the triangle inequality might be a feature rather than a bug.