Sometimes a graph looks wiggly because it’s actually quite flat.
This isn’t much of a paradox; the resolution is quite simple. A graph may look wiggly because the scale is wrong. If the graph is flat, graphing software may automatically choose narrow vertical range, accentuating noise in the graph. I haven’t heard a name for this, though I imagine someone has given it a name.
Here’s an extreme example. The following graph was produced by the Mathematica command Plot[Gamma[x+1] - x Gamma[x], {x, 0, 1}].
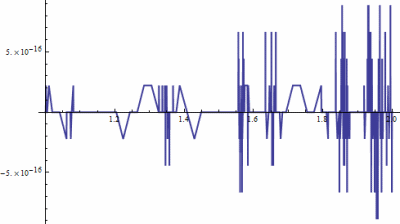
This is unsettling the first time you run into it, until you notice the vertical scale. In theory, Γ(x + 1) and x Γ(x) are exactly equal. In practice, a computer returns slightly different values for the two functions for some arguments. The differences are on the order of 10−15, the limit of floating point precision. Mathematica looks at the range of the function being plotted and picks the default vertical scaling accordingly.
In the example above, the vertical scale is 15 orders of magnitude smaller than the horizontal scale. The line is smooth as glass. Actually, it’s much smoother than glass. An angstrom is only 10 orders of magnitude smaller than a meter, so you wouldn’t have to look at glass under nearly as much magnification before you see individual atoms. At a much grosser scale you’d see imperfections in the glass.
The graph above is so jagged that it demands our attention. When the horizontal axis is closer to the proper scale, say off by a factor of 5 or 10, the problem can be more subtle. Here’s an example that I ran across yesterday.
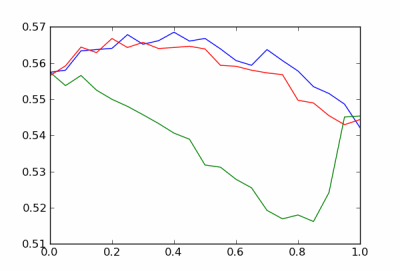
The curves look awfully jagged, but this is just simulation noise. The function values are probabilities, and when viewed on a scale of probabilities the curves look unremarkable.