The previous post looked at Gray code, a way of encoding digits so that the encodings of consecutive integers differ in only bit. This post will look at how to compute the inverse of Gray code.
The Gray code of a non-negative integer n is given by
def gray(n):
return n ^ (n >> 1)
Bit-level operations
In case you’re not familiar with the notation, the >> operator shifts the bits of its argument. The code above shifts the bits of n one place to the right. In the process, the least significant bit falls off the end. We could replace n >> 1 with n // 2 if we like, i.e. integer division by 2, rounding down if n is odd. The ^ operator stands for XOR, exclusive OR. A bit of x ^ y is 0 if both corresponding bits in x and y are the same, and 1 if they are different.
Computing the inverse
The inverse of Gray code is a more complicated. If we assume n < 232, then we can compute the inverse Gray code of n by
def inverse_gray32(n):
assert(0 <= n < 2**32) n = n ^ (n >> 1)
n = n ^ (n >> 2)
n = n ^ (n >> 4)
n = n ^ (n >> 8)
n = n ^ (n >> 16)
return n
For n of any size, we can compute its inverse Gray code by
def inverse_gray(n):
x = n
e = 1
while x:
x = n >> e
e *= 2
n = n ^ x
return n
If n is a 32-bit integer, inverse_gray32 is potentially faster than inverse_gray because of the loop unrolling.
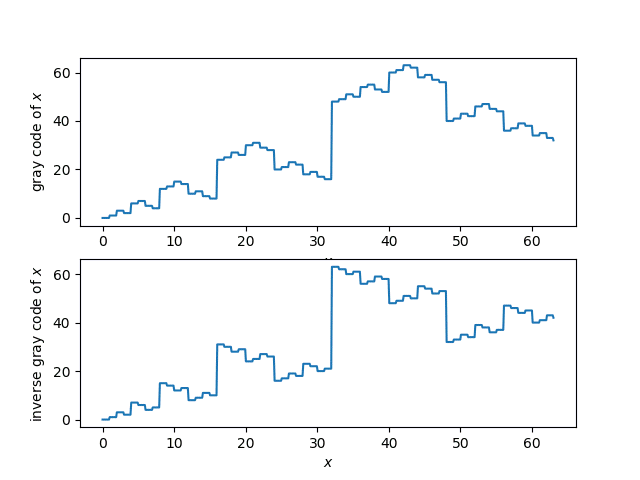
Plots
Here’s a plot of the Gray code function and its inverse.
Proof via linear algebra
How do we know that what we’re calling the inverse Gray code really is the inverse? Here’s a proof for 32-bit integers n.
def test_inverse32():
for i in range(32):
x = 2**i
assert(inverse_gray32(gray(x)) == x)
assert(gray(inverse_gray32(x)) == x)
How is that a proof? Wouldn’t you need to try all possible 32-bit integers if you wanted a proof by brute force?
If we think of 32-bit numbers as vectors in a 32-dimensional vector space over the binary field, addition is defined by XOR. So XOR is linear by definition. It’s easy to see that shifts are also linear, and the composition of linear functions is linear. This means that gray and inverse_gray32 are linear transformations. If the two linear transformations are inverses of each other on the elements of a basis, they are inverses everywhere. The unit basis vectors in our vector space are simply the powers of 2.
Matrix representation
Because Gray code and its inverse are linear transformations, they can be defined by matrix multiplication (over the binary field). So we could come up with 32 × 32 binary matrices for Gray code and its inverse. Matrix multiplication would give us a possible, but inefficient, way to implement these functions. Alternatively, you could think of the code above as clever ways to implement multiplication by special matrices very efficiently!
OK, so what are the matrices? For n-bit numbers, the matrix giving the Gray code transformation has dimension n by n. It has 1’s on the main diagonal, and on the diagonal just below the main diagonal, and 0s everywhere else. The inverse of this matrix, the matrix for the inverse Gray code transformation, has 1s on the main diagonal and everywhere below.
Here are the matrices for n = 4.

The matrix on the left is for Gray code, the next matrix is for inverse Gray code, and the last matrix is the identity. NB: The equation above only holds when you’re working over the binary field, i.e. addition is carried out mod 2, so 1 + 1 = 0.
To transform a number, represent it as a vector of length n, with the least significant in the first component, and multiply by the appropriate matrix.
Relation to popcount
It’s easy to see by induction that a number is odd if and only if its Gray code has an odd number of 1. The number 1 is its own Gray code, and as we move from the Gray code of n to the Gray code of n+1 we change one bit, so we change the parity of the the number of 1s.
There’s a standard C function popcount that counts the number of 1’s in a number’s binary representation, and the last bit of the popcount is the parity of the number of 1s. I blogged about this before here. If you look at the code at the bottom of that post, you’ll see that it’s the same as gray_inverse32.
The code in that post works because you can compute whether a word has an odd or even number of 1s by testing whether it is the Gray code of an odd or even number.