The weakest link in the privacy of cryptocurrency transactions is often outside the blockchain. There are technologies such as stealth addresses and subaddresses to try to thwart attempts to link transactions to individuals. They do a good job of anonymizing transaction data, but the weak link may be metadata, as is often the case.
Cryptocurrency nodes circulate transaction data using a peer-to-peer network. An entity running multiple nodes can compare when data arrived at each of its nodes and triangulate to infer which node first sent a set of transactions. The Dandelion protocol, and its refinement Dandelion++, aims to mitigate this risk. Dandelion++ is currently used in Monero and a few other coins; other cryptocurrencies have considered or are considering using it.

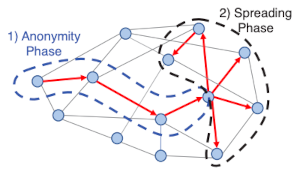
The idea behind the Dandelion protocol is to have a “stalk” period and a “diffusion” period. Imagine data working up the stalk of a dandelion plant before diffusing like seeds in the wind. The usual P2P process is analogous to simply blowing on the seed head [1].
During the stalk period, information travels from one node to one node. Then after some number of hops, the diffusion process begins; the final node in the stalk period diffuses the information to all its peers. An observer with substantial but not complete visibility of the network may be able to determine which node initiated the diffusion, but maybe not the node at the other end of the stem.
A natural question is how this differs from something like Tor. In a nutshell, Tor offers identity protection before you enter a P2P network, and Dandelion offers identity protection inside the P2P network.
For more details, see the original paper on Dandelion [2].
Related posts
[1] The original paper on Dandelion uses a dandelion seed as the metaphor for the protocol. “The name ‘dandelion spreading’ reflects the spreading pattern’s resemblance to a dandelion seed head and refers to the diagram below. However, other sources refer to the stalk and head of the dandelion plant, not just a single seed. Both mental images work since the plant has a slightly fractal structure with a single seed looking something like the plant.
[2] Shaileshh Bojja Venkatakrishnan, Giulia Fanti, Pramod Viswanath. Dandelion: Redesigning the Bitcoin Network for Anonymity. Proceedings of the ACM on Measurement and Analysis of Computing Systems, Volume 1, Issue 1 Article No.: 22, Pages 1–34. Available here: https://doi.org/10.1145/3084459.