The most common way of measuring information is Shannon entropy, but there are others. Rényi entropy, developed by Hungarian mathematician Alfréd Rényi, generalizes Shannon entropy and includes other entropy measures as special cases.
Rényi entropy of order α
If a discrete random variable X has n possible values, where the ith outcome has probability pi, then the Rényi entropy of order α is defined to be

for 0 ≤ α ≤ ∞. In the case α = 1 or ∞ this expression means the limit as α approaches 1 or ∞ respectively.
Rényi entropy of continuous random variable
The definition of Rényi entropy can be extended to continuous random variables by
![]()
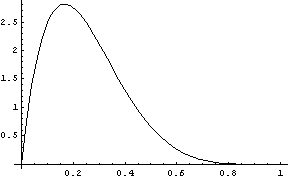
but unlike the discrete case, Rényi entropy can be negative for continuous random variables, and so Rényi entropy is typically only used for discrete variables. For example, let X be the random variable defined on [1, ∞) with density
![]()
Then
![]()
Special cases
Each value of α gives a possible entropy measure. All are additive for independent random variables. And for each discrete random variable X, Hα is a monotone non-decreasing function of α.
Max-entropy: α = 0
Assume all the probabilities pi are positive. Then the H0 is known as the max-entropy, or Hartley entropy. It is simply log2n, the log of the number of values X takes on with positive probability.
Shannon entropy: α = 1
When α = 1 we get the more familiar Shannon entropy:

Collision entropy: α = 2
When the order α is not specified, it’s implicit default value is 2. That is, when people speak of Rényi entropy without qualification, they often have in mind the case α = 2. This case is also called collision entropy and is used in quantum information theory.
Min-entropy: α = ∞
In the limit as α goes to ∞, the Rényi entropy of X converges to the negative log of the probability of the most probable outcome. That is,
![]()
Relation to Lebesgue norms
Let p without a subscript be the vector of all the pi. Then for α not equal to 1,
![]()
As with Lebesgue norms, you use varying values of the parameter to emphasize various features.
More information theory posts
- Why Kullback-Leibler divergence is not a distance
- Bits of information in a US zip code
- Information theory clarifies data discussions
This post was a warm-up for the next post: Rényi differential privacy.